- 🇬🇧United Kingdom catch
Tagging.
This approach would also remove file_exists() calls on every request that renders any js or css. On shared hosting there may well be i/o issues, on sites with more than one web head, css and javascript aggregates will nearly always be on NFS - and there's no file_exists() stat/realpath caching with NFS, so there will be i/o issues too. I've seen those file_exists() take as much as 7% of some requests, and this on a system where there was zero load from other requests. Due to this, bumping to major.
In irc sun suggested this should be a contrib module before a core patch so it can be tested in the wild easily first, that might be a decent option.
- 🇬🇧United Kingdom catch
http://drupal.org/project/agrcache - 7.x contrib module.
- 🇺🇸United States moshe weitzman Boston, MA
Seems like a terrific initiative. +1
the more i think about it, the more i like this.
one thing that occurs to me is that the hash is just as unique if built off the files *pre-regex* as after, so we can simply ditch all that in the page request, including skipping all the gumph in drupal_load_stylesheet_content().
using md5() on the contents looks like the right way to make the hash (rather than another totally braindead use of a strong crypto for no good reason), but i guess we've already lost that battle.
so, a snippet like this could work:
$contents = ''; foreach ($css as $stylesheet) { if ($stylesheet['type'] == 'file' && file_exists($stylesheet['data'])) { $contents .= file_get_contents($stylesheet['data']); } } $filename = 'css_' . md5($contents) . '.css'; variable_set('css_cache_' . $filename, $css); return $filename;but if we're going to make such big changes, i think we should consider the incrementing a counter proposals floating around before. this would allow us to punt on hashing the contents entirely - we could just hash an ordered list of filenames.
- 🇬🇧United Kingdom catch
I'm a bit split on incrementing the counter. While it would save some mucking about here, css/js files change quite infrequently, and incrementing a counter every update.php run or similar would runs the risk building new versions of files more often than we need to. However we could possibly hash each css file that we know about when incrementing the counter, and only do so if one has changed? That'd make it part of a genuine rebuild operation rather than just on misses, then the actual map could be based on the list of files.
- 🇬🇧United Kingdom catch
I liked the idea of hashing based on contents prior to preprocessing, so committed to agrcache here: #1040492: Use unprocessed contents of files for css hashes → .
Don't have any more ideas for that module at the moment, so will bring the code back to a core patch here fairly soon unless something crops up.
Also I saw #352951: Make JS & CSS Preprocessing Pluggable → again recently, if we move to pluggable preprocessors (or the very interesting idea mooted in that issue of moving to a text format-style mechanism where you can chain different filters together), then that is going to massively increase the processing for each individual file, so it makes even more sense to do it outside the main page request.
- 🇺🇸United States mfer
reposting over here....
I was thinking a little further on #1. If we take a look at what espn.go.com does we see something like:
<link rel="stylesheet" charset="utf-8" media="screen" href="http://a.espncdn.com/combiner/c?v=201010121210&css=global_reset.r1.css,base.r228.css,modules.r424.css,global_header.r38.css,modules/global_nav.r47.css,/espn/espn/styles/frontpage_scoreboard_10,modules/insider_enhanced.200910131831.css,sn_icon_sprite.200907150955.css,mem2010/mem.r5.css,mem2010/mem_espn360.r2.css,universal_overlay/universal_overlay.css,universal_overlay/media_overlay.css,universal_overlay/video_overlay.css,universal_overlay/photo_overlay.css,universal_overlay/dyk_overlay.css,warvertical12a.css,twin.css" /> ... <script src="http://a.espncdn.com/combiner/c?v=201012011221&js=jquery-1.4.2.1.js,plugins/json2.r3.js,plugins/teacrypt.js,plugins/jquery.metadata.js,plugins/jquery.bgiframe.js,plugins/jquery.easing.1.3.js,plugins/jquery.hoverIntent.js,plugins/jquery.jcarousel.js,plugins/jquery.tinysort.r3.js,plugins/jquery.vticker.1.3.1.js,plugins/jquery.pubsub.r5.js,ui/1.8.2/jquery.ui.core.js,ui/1.8.2/jquery.ui.widget.js,ui/1.8.2/jquery.ui.tabs.js,plugins/ba-debug-0.4.js,espn.l10n.r8.js,swfobject/2.2/swfobject.js,flashObjWrapper.r7.js,plugins/jquery.colorbox.1.3.14.js,plugins/jquery.ba-postmessage.js,espn.core.duo.r50.js,espn.mem.r15.js,stub.search.r3.js,espn.nav.mega.r24.js,espn.storage.r6.js,espn.p13n.r9.js,espn.video.r33a.js,registration/staticLogin.r10-14.js,espn.universal.overlay.r1.1.js,espn.insider.r5.js,espn.espn360.stub.r9.js,espn.myHeadlines.stub.r12.js,espn.myfaves.stub.r3.js,espn.scoreboard.r4.js,%2Fforesee_v3%2Fforesee-alive.js&debug=false"></script>We could do something like:
script src="http://example.com/files/js/js_hash12342341234234?files=misc/jquery.js,misc/jquery.once.js,misc/drupal.js"></script>The hash would be built like it is now and the combiner could know the files to use. This could be easily cached by the browser and we could test to make sure the files generate the right hash for security. I even like that it documents what files are included in the hash as it can be a pain to discover when you do need to know.
- 🇬🇧United Kingdom catch
mfer asked about the hash lookup at #1048316: [meta] CSS and Javascript aggregation improvement → .
What I'm doing is keeping the same lookup array as core does with $hash => $filename (since the $hash is built from the css/js definitions, but the filename is built from the contents of the files).
But I also keep a lookup array of filename => css/js definitions as well.
When rendering links to css/js, we only need hash to filename. When building css/js aggregates, we only need filename => css/js definition arrays.
When you hit the callback, it takes the filename, looks up the css/js definitions, and can then proceed to build the aggregate using that information.
One @todo is to not store the filename => css/js definition arrays in the variable system, since we don't need to load that apart from in the callbacks themselves, so it's a waste of memory having it there and pulling it back every page. This is a general issue with the variables system though, and could also be handled by #987768: [PP-1] Optimize variable caching → - although need to write up why on that issue, will do that now too...
edit: current code http://drupalcode.org/viewvc/drupal/contributions/modules/agrcache/agrca...
- 🇺🇸United States mfer
When the function that creates the script tag is called it could write something to a table that contains a list of the files for that hash. It would be a really fast lookup. But, how do you keep that table cleaned up? If you just write to if forever it could grow to be big. You can't truncate it like a cache table because there could be a cached page (in a browser) that tries pulling to a file that no longer exists and we don't have the data to generate.
Basically, there are multiple race conditions that can occur (one is even noted in the agrcache code comments). We should build a sub-system without the race conditions.
- 🇺🇸United States mfer
If we did something like:
<script src="http://example.com/files/js/js_hash12342341234234?files=misc/jquery.js,misc/jquery.once.js,misc/drupal.js"></script>We could generate the hash based on the file names + predictable details for the script tag. Then, when we go to generate the file we check the passed in hash against a new hash created based on the name + predictable details. If they match we generate the file. If not, we don't. This would stop misuse of this combiner.
A method like this could be used to remove the db lookup and some of the noted race conditions. The only race condition I currently see would be the file existing/generation between multiple requests at the same time.
Thoughts?
- 🇫🇷France pounard
Never let your logic be controlled by GET parameter or URL generation logic. Aggregation and menu callback should let visible as URL's only server side computed hashed. On a production site, the variable will never grows since all hashes will already have been generated on most pages.
If the URL building logic is predictable you can then have malicious hack attempt or DDoS attacks based on that.
There is nothing ugly about storing hashes with associated files array in server side as long as you don't generate different aggregated file on every page (which is quite dump thing to do). The whole aggregation goal is to have the less files possible it can have to ensure that a single client browsing on site won't fetch a new CSS and JS file each new page it comes to.
- 🇺🇸United States mbutcher
I'm a little unclear on one thing: What's to keep the filesystem from being filled by thousands and thousands of rendered stylesheets from days of yore? On our site we regularly see hundreds of variants of an aggregated CSS file. As small tweaks are made to CSS, more and more unique hashes will be generated, and more and more files will be generated.
Against the need to prevent massive numbers of CSS/JS files from filling up the filesystem, there's the concern that we should not simply delete CSS/JS files with each cache clear. Why not? Because external caches (Akamai, Varnish, other people's proxy caches, etc) may keep their own copies of cached pages still referring to older versions of the stylesheets. Attempting to manage CSS/JS files by simply deleting old ones when a new one is created causes huge problems for large sites with distributed caches.
- 🇫🇷France pounard
You don't have that many solutions. If you want to limit the number of generated files, then you have the files to be the more static as possible as you can.
If I was an horrible dictator, I would force the whole CSS/JS handling to be highly declarative (each module would have to expose their own CSS and JS files in a declaritive way, either in the .info or in a custom hook) then I would aggregate all of them on every page, and this problem would be solved.
Because sometimes, for some execptions, some files should not be aggregated on every page (and the dynamic inclusion should be the exception in a static oriented pattern, the actual D7 core pattern is upside down) then some options for controlling that should be declared in this files registry, statically again.
Plone works this way as I understood.
Static register of every CSS and JS files would allow you to make the aggregated files fully predictable, then the dynamic bits of it would be the exceptions in the pattern, and you could treat it differently (maybe not aggregating them at all would be a simple solution). It would also allow sysadmins to override the aggregated files and profiling the aggregation the way that fits more to their physical environment.
- 🇺🇸United States mbutcher
I like mfer's suggesting in 14. But we might need one more thing in the hash.
Say we have foo.js. On version 1.0 of the code that uses foo.js foo.js calls bar(). On version 1.1 of the code, bar() is removed from foo.js.
Now, consider the case where we are using an external page cache (Varnish, Akamai, etc.). Because a Drupal cache clear cannot clear all of the nodes on Akamai's network -- or even on Varnish -- we will for some time have pages cached in the external cache that are still using version 1.0. The removal of bar() in 1.1 will cause all of those pages to break.
So we would probably need one more piece of information in the hash (at least) or elsewhere in the GET string.
- 🇫🇷France pounard
If you update to 1.1 your lib, and the hash i based on md5'ing the files, then the hash changes and the cache will be refreshed. Akamai and Varnish cache will gracefully die after their TTL or when their memory will be filled by new data. I don't see no problem with using nothing else but a single hash, depends on how you compute it.
And again, that's not a real problem, you don't update a production site every day. When you do update a production site, you are going to have problems with reverse proxy cache anyway, whatever happens at least during the page TTL.
EDIT: Again, we can afford md5'ing the files because it will happen only when the site is in development. Once the site is put in production mode, every hash will already have been computed. JS and CSS files are not something that evolves like you data, there is no dynamism at all.
- 🇺🇸United States mbutcher
Incidentally, how we solve the deletion of CSS/JS files is to run a cron that checks the atimes on aggregated files and deletes files that have not been accessed in over X hours/days.
- 🇫🇷France pounard
Or just let the site admin press a button to tell the system he manually updated a module.
- 🇫🇷France pounard
I know that Drupal core developers are emotionally attached to high dynamism, but the CSS/JS case, we are talking about pure static files, that will never, ever be modified except if modules are updated. When modules are physically updated, then wipe out the aggregated files cache, that should be more than enough.
- 🇺🇸United States mfer
When you update production you should NOT have trouble in your reverse proxy. We need to serve both the small and large clients in this.
Creating the hash would use the files plus some "predictable details". This could include elements like a private site key and css_js_query_string. I'm not entirely sure what would be appropriate here as we need to explore a little more.
- 🇺🇸United States mbutcher
@Poundard
And again, that's not a real problem, you don't update a production site every day. When you do update a production site, you are going to have problems with reverse proxy cache anyway, whatever happens at least during the page TTL.
What I am talking about is completely missing JS and CSS. We regularly release production code updates that do not break because of external caches. This should be the norm for un-hacked Drupal.
When CSS/JS aggregated files go missing because of a minor changes, the site goes unstyled, the ads don't show up, and features don't work. Unacceptable. Period.
- 🇫🇷France pounard
When CSS/JS aggregated files go missing because of a minor changes, the site goes unstyled, the ads don't show up, and features don't work. Unacceptable. Period.
Using a MD5 hash of the files themselves to create the CSS/JS files hashes leads to no cache hits the first time then never ends up with a blank site.
Then again, serving a 1 day TTL'd cached page will then give the oldest outdated CSS file hash, that would the same TTL than the page itself. Then you have 2 different choices here, either you keep outdated files some days (but mark them somewhere as being outdated so you can remove them later) or just put a higher TTL on them to ensure that cached outdated pages will live less time than them.
There are probably a lot of other solutions, and that's not the real problem here. You don't need anything than a hash, you don't need GET parameters, the problems we are currently arguing about right now is nothing resolved by the hash itself.
- 🇫🇷France pounard
I'd prefer to speak about the original issue, which is nothing such as the files TTL. We are talking about how to generate them, not about how to remove them. The deletion algorithm can be implemented outside this issue, and can be über complex if you want to, it does not belong to this thread IMHO.
- 🇺🇸United States mfer
When the hash is created it could be files + unique site key + query string (updated on each cache clear). That would be easy to block from people trying to use the combiner from the outside and work with reverse proxies (I think).
- 🇫🇷France pounard
A physical fileS MD5 is almost as hard to guess that the answer of what is the universe. I won't worry about this.
The only thing that really stops the DDoS is server side check in order to know if the hash has been registered or not (like the form tokens for example), the registration must a server generated hash, some sort of unique id. If a user try to DDoS you with an existing one, it'll just try to DDoS the CDN :) If a user tries with a non existing hash, it'll just the exact same as flooding your full homepage, you just can't stop it.
The only thing I warned you about is that the server should not respond to client orders (what I mean here is that the file selection should not come from any specific client URL but should be pre-determined by the server itself).
EDIT: Better expression.
- 🇺🇸United States mbutcher
@mfer: Yeah. That would work. Though you might still need some version string or timestamp to prevent a new aggregated file from overwriting an old one (assuming you're still talking about file *names* in the hash).
- 🇺🇸United States mfer
Maybe we look into a method using the most recent time a file was updated as part of the process. A file to be aggregated that is.
- 🇺🇸United States mfer
@pounard Form tokens don't stop a ddos. If you want to stop a ddos get the IP (or range) doing the damage and block it at a level much lower than the application.
- 🇫🇷France pounard
#31, #32 and a lot of other posts: We are not arguing the right details here. Core aggregated files naming is the only good part of core aggregation mecanism and I really don't see why changing it. I might have expressed myself wrongly at start.
- 🇬🇧United Kingdom catch
@mfer's #13. That is essentially what agrcache is doing now, it has the same strengths and limitations as the current core method more or less.
The race condition that's documented in agrcache is just documenting the workaround for the existing race condition in any code in Drupal 6 or 7 that uses variable_set(). All agrcache is doing there is reducing the window by several hundred milliseconds to one or two. Issues dealing with that are #987768: [PP-1] Optimize variable caching → and #973436: Overzealous locking in variable_initialize() → . I need to generalize the variable_get_from_storage() and _add_to_variable() functions into another issue somewhere, or one of these.
If we went with the filename appendage for hash lookups, then it looks like we can remove storing the information about the files to be aggregated. However I'm pretty sure we can't avoid storing the hash => filename lookup that core has already (and we'd need to be able to do reverse lookups efficiently, although array_search() on a cache miss might not be too bad). That suffers from the exact same race condition I'm trying to minimize in that code, where one process can 'delete' items from the array that's just been saved by a previous process. Locking here is dangerous since this is all in the critical path. So while it's relevant here, it's really something to be solved in the variables system itself.
Currently we hash filenames on every request to get the filename (not too expensive). And the filename is generated from a hash of the actual contents of those files (very expensive but only done once or twice). The other option would be a strict versioning system for every css and js file, or arbitrarily raising a counter each flush, or just relying on the filenames, but then you either risk not updating when the contents change, or updating too often by changing the hash too aggressively even though the files haven't changed. Whichever way there's going to be a trade-off, and this part of the current logic is actually really good. Also we can't add versioning for non-libraries to Drupal 7 and I'd like to get at least some of these improvements in there so that people's sites stop going down or taking extra seconds to load.
The way core uses to work around deleted files being linked from cached pages, and which answer's Matt Butcher's question in #16 is http://api.drupal.org/api/drupal/includes--common.inc/function/drupal_cl... and http://api.drupal.org/api/drupal/includes--common.inc/function/drupal_cl.... The default 'stale' age for an aggregate is 30 days - so that partially deals with cached pages requesting old file names, since they will often be there (but not always). (This indirectly points out a bug in agrcache since I don't have anything to delete the variable in there yet and they're named differently to the core ones to avoid conflicts on enable/disable). You could raise that limit a bit (say to 300 or so), but if you don't rely on existing files and/or a hash in the database, then you get precisely into the situation pounard describes where if you always guarantee a file will be available at that address under any circumstances, you're open to ddos or have to make other trade-offs. If we store hashes in the database (for some length of time), then there shouldn't be a ddos though, since if the hash doesn't exist, you just throw a 404, and it's easy to trigger a 404 in Drupal.
There's a tonne of comments still left, and looks like more posted since I started typing this, so more later..
- 🇬🇧United Kingdom catch
Now, consider the case where we are using an external page cache (Varnish, Akamai, etc.). Because a Drupal cache clear cannot clear all of the nodes on Akamai's network -- or even on Varnish -- we will for some time have pages cached in the external cache that are still using version 1.0. The removal of bar() in 1.1 will cause all of those pages to break.
Er, yes it can. http://drupal.org/project/varnish and http://drupal.org/project/akamai support doing exactly that.
If we really care about this issue beyond the problems that already have a solution, then we just need to consider whether other caches (local proxies, google cache, web archive) will also cache the css/js files along with the page, or call back to the site. Some might, some won't. Then it's a question of "should Drupal support indefinite caching of HTML by third parties we have no control over who expect to be able to link back to assets from the original site in perpetuity", which is a feature request. Like pounard says that's the wrong detail to be discussing here and if you really want to discuss that in depth please open a new issue, since it has nothing to do with changing the mechanism of aggregate generation which is what this issue is for.
- 🇬🇧United Kingdom catch
When the hash is created it could be files + unique site key + query string (updated on each cache clear).
No arbitrary query strings please, see #9 - we'd then be invalidating CDN and browser caches every time someone sneezes. I could live with a counter that only gets incremented if files have changed, but that means keeping some record of if the files have changed or not over time, which is a whole separate issue again.
- 🇺🇸United States mfer
@catch thanks for the detailed explanation. It helped clarify where you come from and I like it. So, here is what I see:
- drupal_get_css() stores the hash and what files are included + inserts script tag into page.
- When the js/css file is generated it looks up the files from the hash in the db and generates the file. Future requests will hit the file instead.
- For cleanup, when the css/js files are deleted after 30 days (or other set time) the record in the database is removed as well.
Does this sound about right?
- 🇺🇸United States mbutcher
@catch Regarding #35, I misspoke. I suppose I was *assuming* that we wouldn't globally invalidate a cache for each code update, which is pretty much necessary to avoid getting slammed with uncached page requests. So, yes, we *could* get Drupal to clear the entire Akamai/Varnish/... cache. But it is preferable to avoid external cache rebuilding for CSS/JS updates. Letting them expire is preferable. And the new staleness code in D7 probably fits the bill.
But you are right, the issue is only tangentially related to this, in that any structuring of the CSS/JS filename needs to be (loosely) version sensitive for the above to work. So as long as that's addressed, I'm fine.
- 🇬🇧United Kingdom catch
@mfer: currently point three of #37 is a little bit different, in core we reset the variable on css/js clears, and at that point delete the files, the files won't be expired any other time iirc. This means that if you never clear css/js on a site, then those files will sit in the file system indefinitely (although also new files won't be added much either so I don't think this is a big deal).
I don't think we want to do any scheduled cleanup, since it doesn't make sense to remove those files /unless/ there's a cache clear either - it's completely valid for an aggregate to be two years old if your site's theme has had no updates. We don't know for sure if those files are valid without the hash, and we don't know if the hashes are valid at all because they're created dynamically - unless there's an explicit flush in which case all current hashes are invalid until they're regenerated. It's also possible for a file to be valid even without a hash in the database - since you can clear the cache, leave files younger than 30 days in the system, and because the filenames are based on contents, they'll continue to be used rather than regenerated - this is why I don't like incrementing a counter since this would stop working, although a manually incremented counter might not do any harm as an option for people to use. Again, the current logic here is pretty good, I'm sure we can tweak it but other parts of aggregation are bigger wins.
- 🇫🇷France pounard
I don't feel this issue shoud live by itself, and that's why I though yesterday:
We have to focus on the simple goal we want to achieve for the full aggregation part
But, we have also secondary goals here
Considering all this points here
I think that is issue should probably be the last one to be fixed within all others.
The first point you have to consider is because you start to think about using the same mecanism as image styles, and talking CDN integration, you have to merge this issue with the image style subsytem one itself. This in order to find one and only technical solution for this, with a common code base. Integrating this problem around the stream wrapper API seems to be the smarter way to do it. To be clear, even the menu callback itself should be a common menu entry over the files directory, for all, and then derivated running code would live in specific stream wrapper implementations for example. Factorise the problem, factorise the solution, and it will work as-is without any code duplication for all the files and CDN integration problems.
This issues does not belong to the CSS/JS aggregation problem, it should be a global pattern in the core for all subsystems tied to the lowest level API possible.
Because of this statement, the CSS/JS aggregation problem should only focus on the first three point I quoted above. Catch already has part of the solution in agrcache module, and I do have some of them in core_library module, let's start thinking with some nice component diagrams and schemas that will be way more understandable that any other potential written argument here.
The first thing on which to concentrate of is to destruct and throw away the actual implementation, and build one, API and backend orientend, static and declarative API, with no I/O and delayed possible aggregated files construction. Then, let people that worked on the stream wrapper implementation solve the real CDN problem on their side. Once they found a solution to this problem, plugging the new fresh aggregation API over it would be something like 2 lines of code, if they did it right.
EDIT: Some typo, sorry for my poor english.
Re-EDIT: <strong>'ed some important parts. - 🇺🇸United States mfer
@catch Let me clarify my 3rd bullet in #37. When we create hashes and store them in the database we shouldn't so that forever. If they are in the variable table or in their own table this is space we don't need to keep filling up. We need a method to remove stale hash entries from the database.
My suggestion (and there may likely be a better way) is to remove the hash data from the database when drupal_clear_css_cache or drupal_clear_js_cache are run and use a similar logic method as drupal_delete_file_if_stale to decide if an item is stale and should be removed from the database.
How did you plan on removing stale hash entries?
- 🇬🇧United Kingdom catch
@mfer: I'd keep it the same as now, the intention here isn't to fix everything about aggregation, just the aggregate generation method.
see http://api.drupal.org/api/drupal/includes--common.inc/function/drupal_cl...
- 🇫🇷France pounard
catch +1 this is a detail, and the solution will come with a new API. We can't solve details without having taken the time of the reflexion of the overall design. Actual solution isn't the best, but at least it works and it's not the main problem here.
- 🇬🇧United Kingdom catch
Also generating the hashes is less expensive in terms of time than generating the files, at least on i/o constrained systems. The main thing is trying to avoid creating more aggregates than necessary. I don't see a nice way to change this with the variable storage, maybe a dedicated table but that's a lot of extra to manage.
- 🇬🇧United Kingdom catch
Here's a patch. Should work except for clean URL support. Haven't run tests yet, leaving that for the bot.
- 🇫🇷France pounard
After a first reading it seems not bad, I'll take a deep look at it later.
- 🇺🇸United States mikeytown2
6.x version that covers just about everything: http://drupal.org/project/advagg If your wondering I've been kicking this idea around in my head for about a year now: http://groups.drupal.org/node/53973. Couple of things this does that might interest this crowd that is not listed in the readme.
- Will test the CDN and non CDN url path to see if the advagg 404 menu hook is called.
- Implements fast 404s on a complete miss.
- Request is sent async to the newly created bundle on page generation. That means the bundle is generating in the background while the page is getting generated on the server... yes multi-threading in short.
- In theory on demand generation will work with clean URLs disabled.I'm sure I've missed some others... in short advagg rocks! Feedback is greatly appreciated.
- 🇨🇦Canada RobLoach Earth
This code is starting to get quite large... Would love to make it all pluggable.
- 🇬🇧United Kingdom catch
Pluggable is good, but I would love to get this into Drupal 7 (since the current logic can bring sites down), then make it all pluggable after that. Pluggable things still need sane defaults, and IMO this is the biggest win we have in terms of performance of this stuff in PHP.
- 🇨🇦Canada mgifford Ottawa, Ontario
I started a thread #1166756: Support for Google's Closure → about using Google's Closure code to optimize jquery & then include those more optimized files rather than those that ship with Drupal.
For me that started with was of leveraging Google's http://code.google.com/apis/libraries/ so that we can all benefit from not having to load this common library with every site.
I'm in favour of encouraging this type of behaviour in the community (but not putting direct links to Google's files in core or anything. It should be an opt-in situation, but if it is then where is the danger of hosting the files off of our own servers?
- 🇺🇸United States mfer
@mgifford This issue is separate from what you are describing. Separate enough it should be discussed in a separate place.
- 🇫🇷France pounard
Hello again! Long time I didn't post here.
I have been doing some work about how the menu system could completely generate files on demand, based on partial file path. I finally ended up with a simple schema that could actually work.
You can see the diagram right here, in order to fully understand it, you might want to read what's next on this post with the diagram open side by side.
Concept
The whole concept is oriented around a fully pluggable system based on interfaces.
@catch: Yes, fully "pluggable".The main concept is split into those two statements:
- Menu doesn't care about specific implementations behind.
- Generated resources are static files, handled by Drupal, with or without a lifetime set.
Definitions
It's based on those definitions, that I arbitrary choosed:
Overall design
The main idea to implement it is to allow any (e.g. ImageStyle, core aggregation system, maybe Views for generating XML, anything that is a module or a core API) to register their providers to the system (See note ).
Each provider has a (provided by the
getDynamicPath()method (See note ).Runtime and error handling
Menu callback catch a lock on full file path (relative to files path). This lock will be released on errors, or when the file handling finished.
If the file is already locked, this callback shouldn't wait, it should either throw a:
- 409 Conflict
- 503 Service Unavailable
This first one seems the best, while the also exists, but it's WEBDAV specifics so we don't want to use it.
The can find which provider to use depending on a set of (extremely basic) rules matching using the partial file path from URL.
Each provider can spawn files instances using the partial relative path, relative to files folder. Never relies on absolute URL.
If the path means something, then it delivers the instance. If not, it throws an exception catched in the menu callback that triggers an HTTP error
- A real 404 this time, because the file really do not exists!
- Or a 500 or 503 error if the exception is not an
VoidResourcePathExceptionbut another technical error for any underlaying package.
This model allow the lowest code indirection possible, and will be extremely fast if no module messes up with
hook_init(), which is the actual bottleneck of most Drupal 404 errors. Of course, Drupal shouldn't be bootstrapped on second attempt but that's up to the CDN/HTTPd/proxy configuration here maybe.Real file handling
The instance can be an , case in which it implements the
DynamicResourceInterface, and is able to give back content.If, in the opposite, it matches a file that should be statically created (non volatile data for the most), then it should be an instance of
DynamicResourceFileInterfacethat will actually also be a direct implementation of core existingStreamWrapperInterface(in most case a public specific implemention, but could any other).
This file instance using the upper named interface has a new method, which isrebuild(). This is purely internals, and should be lazzy called by the instance itself, after checking withexists()(See note ).The menu callback would not be aware the distinction exists, it would just return the
getContent()call, whatever happen (this is where to plug the lazzy rebuild for file-based implementation).Each resource is able to give a lifetime (which can be ) this will help the system to give the right HTTP headers.
Magic pathes and ruleset
So I described pretty much of it, now there is something more for you to understand, a schema of the path ruleset applied:
http://mysite.com/sites/default/files/aggregate/css/SOMEUNIQUEID.css | | | We will ignore this. Ruleset! File identifierLet's see that again:
http://mysite.comis base URL, throw it.
sites/default/filesis file path, throw it.
aggregatedesignate our provider (registered partial path).
css/SOMEUNIQUEID.cssfile path given to provider (identifier).So, we could have conflicts, basically. Imagine I do an image aggregator which registers:
aggregate/images(this is valid), it would conflict with the already registeredaggregatepartial path.The solution here (what I call the ) is basically to determine which one to use by parsing the partial path from the most specific towards the most generic.
Example: I give this URL to my menu callback:
http://mysite.com/sites/default/files/aggregate/images/foo.png
The discovery will based on a pre-ordered list of potential conflictual partial pathes when registering the providers (we probably would need cache then, but not that sure, needs benchmarking):- aggregate/images
- aggregate
- imagestyle
Will then test the URL's one by one (either using substrings, either using regexes) in order to find the right one in order (See note ).
So if I give the URL quoted above, you will get this:
Now, if I give:
http://mysite.com/sites/default/files/aggregate/css/foo.css
This would give:
Providers are magic? CSS and JS specifics
Absolutely not! Each provider should carry its own business code.
The simplest example is for CSS and JS aggregation. Actually when core derivate a new JS/CSS file, it build a hash of the new file.
The CSS/JS implementation should build a random and unique identifier (See note ) and store it in a database table, along with the full file list. Then, on menu callback call it can restore it and build the real file. The beauty of this model is once it's build, we will never query again the database because HTTPd will catch the real static file (See note ).
These files entries must not be cached in a bin, but in a real table once the JS/CSS aggregation derivated to a URL, this must be non volatile in order to handle further requests from outdated browser's or proxies cache.
And what now?
Give 1 hour, I make you the code for the original design.
Give 2 extra hours, I make the CSS/JS partially working.
Give 3 extra hours, I overload the actual Image Style handling, do the menu alter, and backport it to D7 gracefully.
Then give me 5 hour of your time, and we all discuss this, fix bugs, evolve the API or throw it away and pass to another solution.Footnotes
- This can be done either using a hook_info(), or in modules .info file, or anyother discovery system, this is where the system becomes fully pluggable and will be integrated with future plugins system discussed into the WSCCI initiative.
- It can also be provided by hook metadata, this not fixed anyway and won't change the hole design.
- Indeed, we could get here because the HTTPd didn't find the file, while another thread could have created it (even with the locking framework, race conditions can happen).
- Substrings would probably be faster, that's why I want the schema to respect the KISS principle (Keep It Stupid Simple) and not implementing the whole matching ruleset using complex parametrable regexes (a lot slower).
- Why not a UUID V4 here, this is exactly the kind of purpose they have been created for.
- Actually the Image Style module (formerly ImageCache for D6) already works this way, we need to keep this!
- 🇫🇷France pounard
Eventually, some additional ideas to get further:
1. Create a directory for (content related static files) and (at the same level) for (dynamic content, not content related, static files or not).
In the long term, separating actual PHP code and remove it from the public web root dir would be a really good idea for security. Files (asset and resources) could then be elsewhere than the folder you commit into you git repositories when you do a project :)
2. Make the modules defines their CSS and JS in a declarative manner (the framework would be able either to move them at install time into the resources dir, either do it on demand with a specific provider and dynamic resource implementation, such as
DefaultModuleCssFileResourceInterfacefor example. - 🇺🇸United States mikeytown2
@pounard
What are your thoughts about my side project http://drupal.org/project/advagg?
In terms of matching the files directory and intercepting it before menu_execute_active_handler fires check out http://drupal.org/project/files_proxy (runs in hook_init). These are done in D6, but once advagg is reaches 1.0, I will be working on a 2.0 release for 7.x; aggregation changed a lot between D6 & D7 so having a 2.x release makes sense. - 🇺🇸United States Owen Barton
Some interesting thoughts so far - using a menu callback for generation is an interesting idea. @catch, have you tried this patch on any production sites?
- 🇫🇷France pounard
@mikeytown #57, I just looked up at advagg code, I think the design I made has pretty much ideas from it, but I think it's because catch originally express those. The main difference is I created an OOP design, much more centric, that mutualize it for anything, instead of having N menu items, my solution would only carry one for everything.
I might have looked at the wrong project branch, though.
Nevetheless that's where my design take an opposite from your module, it's interface centric and highly pluggable. It totally decouples business logic from the way to achieve it, and gives a set of extremely basic interfaces to ensure pure business code won't bother the middle complexity (which I solved partially) such as testing the file existence, locking, etc..
- 🇺🇸United States mikeytown2
@pounard
I never use master; here is the 6.x-1.x Tree. advagg.missing.inc is what your interested in most likely.In terms of the files existence, htaccess handles that; I use locks.inc for locking; it stalls then 307's once the file is generated.
- 🇫🇷France pounard
I have been working on http://drupalcode.org/project/core_library.git/tree/67dd838 (module Core Library). I actually implemented the schema upper, and written a totally useless sample implementation as well as the core CSS override (using #aggregate_callback override from style element info). It actually works quite well.
See the sub module 'resource' in http://drupalcode.org/project/core_library.git/tree/67dd838:/modules/res... for the implementation details (the lib/resource.inc file is where you should find the real useful code, as in the resource.module file you will find the deliver callback).
The implementation does not really fit the diagram I did the other day, but it looks pretty much like it, except I added the dynamically generated file $uri in the center of the design (which provide the link with the stream wrapper API) and removed the direct inheritance link with stream wrappers (much more cleaner).
@#60 Your module does *a lot* more than this, but I wanted to keep a simple implementation (while fully pluggable) that actually matches the issue's title.
- 🇫🇷France pounard
Did an alpha2 release (that will come in 5 minutes), and updated class diagram to fit the code.
Pretty much same discovery mecanism as upper except I did put the URI and Stream Wrapper in the center of the design. Each public local stream wrapper sees it's base directory path handled by one registry (registries are singletons, on a per scheme basis). Providers can basically work on all schemes, this has really no importance, this is decoupled and allowed by design. A shortcut method of the registry allows to spawn resources directly (internally spawning the provider) which take cares of full and final resource URI build and pass.
File based resources are no longer extending the stream wrapper API (it was a huge mistake on my first diagram), but as each resource (not only files, all resources) have a fully qualified URI, you can use the adapted stream wrapper really easily. It makes the file based resources an unneeded abstraction, but it exists for code mutualization.The overall code weight is 1000 lines, including CSS and JS integration, as well as Image Style file generation (basically OOP rewrite of the actual core menu callback), file delivering, HTTP headers handling, some basic configuration screens and form alters, a custom stream wrapper implementation, and all is fully documented (documentation included in the line count).
If anyone has some time to check/review/hate what I done, I'd be pleased to have some feedback.
EDIT: Just released an alpha3, this particular one solves the CSS and JS files modification problem. A version string is preprend to the URL (method used by some other software). When cache are cleared, each files of a computed map are being checked (once per hash only), if at least one of the files have a mtime superior to database entry creation, the version number is incremented. If a race condition happen (it can, it's not thread safe), the version string will be happened twice (which should make the whole stuff work anyway).
- 🇺🇸United States mikeytown2
@pounard
You should also include md5 if you haven't done so as a way to test if a file has changed. Not all filesystems keep an accurate mtime. Do you want to team up? Sounds like your starting to port a lot of advagg's code into D7 & into your module. I already have my first request for D7 version of advagg [#31171546]. We both have the same goal, we should work together. PS you need to call clearstatcache() before using filemtime(). - 🇫🇷France pounard
Problem with file md5 is that it will be a lot slower. If the mtime is not accurate on the system, it should probably be overridable with an option (variable?).
Your module does a lot more than mine, and actually does not the same way! I'm totally pro-merging efforts if you want to, but we need to discuss how before.
EDIT:
@mickeytown2, I'm going to look more deep into your code in order to see where the patterns fit and how we could potentially merge. Don't hesitate to pm on IRC or mail via my contact page.My code still remains a PoC of what could be such system in core, not sure the merge is something I want right now, but as promised, I'm going to study it.
- 🇬🇧United Kingdom catch
A real 404 this time, because the file really do not exists!
Or a 500 or 503 error if the exception is not an VoidResourcePathException but another technical error for any underlaying package.I'd rather wait here - it's good to avoid stampedes, but we should go ahead and serve something to the unlucky requests.
And/or, generate the resource and serve it, but don't try to write to the filesystem on lock misses.
The solution here (what I call the ruleset) is basically to determine which one to use by parsing the partial path from the most specific towards the most generic.
The router system already handles this, so I'd rather use what it does there rather than re-implement it - there are not going to be dozens and dozens of resource callbacks, we have three potentials in core right now (css, js image derivative).
Three different custom implementations of this (assuming we do this for css/js at all) is definitely enough to warrant adding an API for it and trying to centralize some of the code. I had a read through core_library and the general approach looks good.
@Owen, I haven't got agrcache running on any production sites, although there is one client that has it in their backlog and I'm hoping will report back.
@MikeyP: hoping to have some time to take a look at advagg soonish.
- 🇫🇷France pounard
@#67 Thanks for feedback. I agree for the menu system, it definitely can use it extensively instead of doing its own path split. I'm not sure it will fully remove the path split (how could we in a generic manner fully handle file extension and subpath). The idea behind the ruleset was leaving to business implementation what belongs to business implementation. This is arguable though. It could at least use the menu for one level deeper (provider level).
The whole goal of this is to centralize all three different ways of doing it into one generic enough to cover all actual needs.
- 🇩🇪Germany donquixote
A note:
I once had some difficulties to make imagecache work with lighttpd.
The reason was that lighty can not be as easily configured to run php only if a file does not exist in this location.I did not try hard enough to say it is impossible (it was not really my job to get this running).
In fact it is supposed to be possible with mod_magnet. http://nordisch.org/2007/2/6/drupal-on-lighttpd-with-clean-urlsAll I want to say here is that a lot of people will run into this issue if this goes into core, and maybe some of them will have difficulties to correctly set up mod_magnet.
- 🇬🇧United Kingdom catch
Since image derivatives are in core already, this doesn't make that problem with lighty any worse.
- 🇩🇪Germany sun Karlsruhe
Related, and will most likely land first: #865536: drupal_add_js() is missing the 'browsers' option →
It looks like there has been some major discussion since the last patch. It would be helpful to incorporate agreed-on adjustments to the plan in the issue summary, and also compile and add a list of remaining discussion items to it (if any).
here's a dirty, dirty patch that implements a PoC don't use hashes just put the paths in the URL approach.
- 🇩🇪Germany donquixote
Btw, in some modules I worked on that did something similar to imagecache (css sprites generation, gradient image generation), I found this pattern to be useful:
$menu['sites/%site_dir/files/...']
instead of
$menu['sites/whatever/files/...']Then a wildcard loader function
function site_dir_load($fragment) { if (realpath("sites/$fragment") === realpath("sites/whatever")) { return TRUE; } }Benefit: It does work for any alias of the sites/whatever dir, not just the "canonical" one.
----------
And re myself #70
I read that lighty has something new, which allows to check for non-existent files, and this does not require mod_magnet. this one is probably worth some real reviews:
- path to css folder is no longer hardcoded, uses configured public files dir
- better docblocks, could definitely be improved
- aggregate files get a query string that changes with cache clears
sun suggested in IRC not doing js until this patch has been accepted, so i've left that out for now.
- 🇺🇸United States moshe weitzman Boston, MA
#77: 1014086-77-css-imagecache.patch queued for re-testing.
The last submitted patch, 1014086-77-css-imagecache.patch, failed testing.
- 🇫🇷France pounard
Further, after some chats on IRC which conforted me in my opinion, I think we should orient this issue towards a generic listener based API approach for all file generation.
The idea would be to have the same mecanism as the Assetic library (thanks Crell for reminding me it exists). We have a listener on the kernel dispatch, it catches requests that matches files pattern, then does whatever it has to do depending on an internal logic in order to restitute a file.
This internal logic is what I was proposing in #55, but it can be different, but we desperatly need to have, at some point, assets handlers and providers which we need to be able to resolve dynamically at the listener/controller level.
We then have two path we could follow:
- Using Assetic, we need someone to take a serious look at this library: it may or may not integrate well with our need
- Implement our own internal logic (which doesn't sound that bad, the only difference with using a generic library is that the generic library will probably be full featured and more flexible)
One of the good sides in this approach is we can do it without having to register any router items. This sounds like a huge win to me.
- 🇩🇪Germany sun Karlsruhe
I'd prefer to move forward with this patch and proposed solution as is.
For potential usage of Assetic, we already have #352951: Make JS & CSS Preprocessing Pluggable → and some other issues (search for Assetic). A couple of limitations (or lacking features) in Assetic have been pointed out already.
Furthermore, for image styles, there's also #1561832: Replace Image toolkit API with Imagine → . Imagine not only covers image toolkits, but also has a built-in concept of generating image derivatives.
In turn, there's a lot to research and figure out in this field, before we can even start to think about harmonization. The idea of harmonizing all of this is a competing proposal, which should live and be discussed in its own issue, in order to not block and derail this issue.
Therefore, I'd really prefer to make pragmatic process here. That yields a concrete result and guaranteed improvement over D7.
- 🇫🇷France pounard
I'm still thinking about making this a more generic API, that would handle both public files, images, css and js, would be a better way to go.
I see multiple issues in this patch:
- Yet another specific piece of code for a more general generic file handling use case
- It doesn't lock when building the CSS files, so we could have concurrent threads doing the same work at the same time, having potential conflicts when saving the files
- [EDIT: misread the patch for this one, sorry, thanks msonnabaum for pointing that out to me]
- The new WSCCI patch which being stabilized at this time introducing the request/response kernel from symfony will also bring a totally new way of handling this, which will make this code obsolete the second it will be commited to core
Going the way I proposed in #55 would reconcile this with the WSCCI initiative, of course my proposal is now obsolete too, but the design is much closer from what we'll have to implement in the end when the WSCCI patch will land.
- 🇫🇷France pounard
This change will be obsolote the second the WSCCI patch will be commited. [EDIT: less than I thought due to a misreading]
- 🇫🇷France pounard
@sun If the patch is a candidate for D7 backport, then just do the patch for D7 already and post it in a new issue set for 7.x, it indeed fixes real world problems, for a real world used version, but it doesn't make any sense for D8 because D8 is not a usable product yet, unfinished, in code as in design since it's in development process.
D8 is not out yet, and this can be solved in a much more elegant and efficent way, and we can do a major cleanup for a minimal cost by sharing the dynamic asset handling with image derivative generation --even if custom and simple, Assetic is yet another topic, more complex indeed--. This is what this issue has derivated to a year ago.
As long as D8 is not feature frozen, this must be designed first, coded later. Any code change makes going back in time difficult is a loss of time and energy for all people that actually wrote and reviewed it. Now is the time to think for D8, not the time to code if it's not thought first.
So, as you proposed, I could open a new issue, you said you will then you be happy to review it, I'm saying no: a lot of talking already happened in this one, there is no way to re-open them another place and start all over again from the beginning: you didn't reviewed the 60 first comments of the thread, or at least you didn't even commented them, I'm guessing you won't do it in another issue either.
I won't wait another year in a new issue that quotes the exact same posts that have been waiting here for a year.
EDIT: Sorry for being a bit nervous about this, but this is really something I did put a lot of effort into. I'd be happy not to see this year trashed away, especially when it tries (and succeeds as a stable module) to solve the exact same "real world problems" nicely, with a more global approach, with additional features (concurrent threads locking amongs other things) this patch actually doesn't solve.
yes, please lets just get this in. locking is already an issue, but this patch decreases the race window, and we can add locking later.
i'm happy to do js next in a similar style, then adapt with follow up patches once the kernel stuff is in.
- 🇬🇧United Kingdom catch
Locking has it's own issue here 📌 Add stampede protection for css and js aggregation RTBC , I deliberately opened this as a separate issue because it's 1. a separate issue 2. the locking patch ended up very complex, 3. a lot of locks that were added to Drupal 7 (such as the read lock on variables) are likely making things worse rather than better for stampedes so they need to be treated carefully.
@pounard, if an issue is not fixed in 8.x, we fix it there first before backporting to 7.x, even if we know that the 8.x code might change completely later. This is because there is zero guarantee that 8.x refactoring will eventually deal with this issue, so we could end up knowingly releasing 8.x with regressions compared to 7.x. See http://drupal.org/node/767608 for lots of reasoning.
In this case, it'd be quite possible to add a generic listener to 7.x and still have inline generation of css/js aggregates. On the other hand if the almost-RTBC patch here gets committed and backported, then we can enforce that it gets converted to a generic listener when one is added, since we'd presumably need to refactor file_transfer().
Also if you look at the patch itself, about 90% of it has nothing to do with actually interpreting the file requests, most of it is refactoring the code that generates the filenames in the first place and moving a few things around, which will be needed regardless.
Side note, concating the filenames together seems good to me, it's also an approach that's close to being compatible with things like https://github.com/perusio/nginx-http-concat (which I've not tried but looks interesting), but pounard brought up a point very early on that this is vulnerable to DDOS attacks, which the current hash-based mechanism that was adapted in previous patches (which is also used in http://drupal.org/project/agrcache) isn't. If we only generate aggregates for files that actually exist (i.e. don't try to aggregate something with a non-existing modules/foo/foo.css) then possible this isn't an issue since there'd be a high, but finite, number of aggregates (and D6/7 have enough issues creating lots of unnecessary aggregate files despite the hash) but would be good to discuss.
I won't wait another year in a new issue that quotes the exact same posts that have been waiting here for a year.
I opened the stampede protection issue in August 2010, nearly two years ago. Comments like this aren't helpful and completely ignore the efforts other people have spent on dealing with this problem.
- 🇫🇷France pounard
In reality this patch sounds better than that since it doesn't just concatenate file names. Still seems a weird way to go. I tried generating 30 random module names, between 5 and 12 char eachs, and use them as file name for CSS also, the current algorithm gives me an approximative 1300 chars length URL. [EDIT: which causes file system problems on my box, and is still really long]
- 🇩🇪Germany donquixote
For the DDoS stuff:
If you look at imagene module, this has permissions to protect it from being used as a free CDN:To prevent others from using your server as a farm for gradient images, and totally wasting your filesystem with all possible permutations of colors, imagene comes with two permissions:
- "see non-existing imagene images" can restrict people from using the server power to generate not-yet-existing images.
- "save imagene images" will prevent generated images from being saved to disk, thus protecting your disk space from being filled with junk.
The idea is that only a person with access to the css files will ever want to generate new images, so this person can be given the necessary permissions. Or, you can grant the permissions to everyone, as long as the site is on a dev server, and restrict to admins when it goes to production.
If these permissions are restricted, a formatted version of an image needs to be visited by an admin/staff, before it can be viewed by a random visitor.
EDIT:
Ok, hashes are probably a more effective and desirable protection.
sites/mysite/files/styles/slider-image/public/slider/slide2.jpg?hash=öalkjüpohp9hoihjnöklajölknmövalj - 🇫🇷France pounard
Agree about th potential DDoS problem, I wasn't even speaking of it. I don't know why switching to the concat method while the real world problem pointed out by the issue original post isn't due to the original hash/list mecanism?
URL have, per specification in the HTTP protocol, no length limit. But I'd like to highlight this: install a Drupal site with 100 modules, half of them brings you a CSS file, you will have URLs concating potentially 50 CSS, with a path length of 50 chars (I took this url as example:
sites/all/modules/contrib/admin_menu/admin_menu.csswhich is not a long one), without taking into consideration the base url and other separators, this makes 50 * 50 = 2500 url length. This goes higher than the 2000 recommended max length for IE support. See http://stackoverflow.com/questions/417142/what-is-the-maximum-length-of-...URL are also keys for caching and routing, in all the HTTP layer (client, proxy, routers, load balancer, proxy cache, CDN, HTTPd, PHP), and using extremely long keys may cause performance issues in any of those layers.
In some cases, the apache rewrite rule testing if a file exists can hit the file system limitations and fail. Even without rewrite, you can potentially hit file system limitations with many OS. This limit can be reached quite easily, see this kind of post for example http://serverfault.com/questions/140852/rewritten-urls-with-parameter-le...
EDIT: See also http://en.wikipedia.org/wiki/Comparison_of_file_systems
Did some research, and it seems those kind of problems can be quite recurring.
Whiie I can see the sexy side of URL concat, I think this is a no go, it doesn't scale, expose direct information about file directory structure of your PHP site, and may lead to weird behaviors and potential DDoS (both with arbitrary URL stressing the PHP side and extremely long URL stressing some browsers).
@catch I was a bit harsh with the "I won't wait another year", sorry again for that.
- 🇺🇸United States moshe weitzman Boston, MA
#80: 1014086-80-css-imagecache.patch queued for re-testing.
- 🇺🇸United States moshe weitzman Boston, MA
As catch said, we don't have stampede protection in current code either so not relevant to this patch. The objection that 'WSCCI will soon change code' is a speculation (i.e. might not land soon or even never land). We don't block good patches for hopes and dreams, however sweet and likely those might be. Ultimately, catch will decide is he wants to delay this. So, back to RTBC, as tests are still passing.
- 🇫🇷France pounard
We can't RTBC a patch that will attempt to write files with names longer than most FS supports. This patch is a no go. For example, ext3 has a limit of 255 chars for a single filename, using this patch, when browsing in the adminstration with standard profile (no modules) the file name is already 125 chars. We can't commit this, if we do, we'll doom a lot of sites.
pounard@blaster:/var/www/d8-git/www/sites/default/files/css [Tue May 15, 00:12] $ ls -al total 44K drwxrwxr-x 2 www-data www-data 4096 May 15 00:12 . drwxrwxrwx 11 pounard pounard 4096 May 15 00:05 .. -rw-rw-r-- 1 www-data www-data 1682 May 15 00:08 core;modules;comment=comment.theme,core;modules;field;theme=field,core;modules;search=search.theme,core;modules;user=user.css -rw-rw-r-- 1 www-data www-data 3864 May 15 00:08 core;modules;system=system.admin.css -rw-rw-r-- 1 www-data www-data 7764 May 15 00:08 core;modules;system=system.base~system.theme.css -rw-rw-r-- 1 www-data www-data 3960 May 15 00:08 core;modules;toolbar=toolbar,core;modules;shortcut=shortcut.theme~shortcut.base.css -rw-rw-r-- 1 www-data www-data 16383 May 15 00:08 core;themes;seven=reset~style.css pounard@blaster:/var/www/d8-git/www/sites/default/files/css [Tue May 15, 00:12] $ php -a Interactive shell php > echo strlen('core;modules;comment=comment.theme,core;modules;field;theme=field,core;modules;search=search.theme,core;modules;user=user.css'); 125 php > ^Dpounard@blaster:/var/www/d8-git/www/sites/default/files/css [Tue May 15, 00:12] $ sudo touch "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaacore;modules;comment=comment.theme,core;modules;field;theme=field,core;modules;search=search.theme,core;modules;user=user.css" touch: cannot touch `aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaacore;modules;comment=comment.theme,core;modules;field;theme=field,core;modules;search=search.theme,core;modules;user=user.css': File name too long pounard@blaster:/var/www/d8-git/www/sites/default/files/css [Tue May 15, 00:12] $ yep, i agree with pounard now, this is not going to work - 256 characters is going to be too short.
- 🇫🇷France pounard
Good to hear. You can do a proper patch without changing the hash algorithm thought. You can use a variable for storing the mapping, but personnally I'd go for a database table, even thought the change would be more invasive (I'm thinking about patch size).
EDIT: I'm still against patching right now but if anyone wants it, you can do it: but it need more minimal than this: using the core hash algorithm and storing into the variable as a first attempt will be only a patch with only a menu callback and no change in the rest of the code.
- 🇬🇧United Kingdom catch
Note #47 is pretty close to this, although that patch is 15 months old now.
- 🇺🇸United States mikeytown2
Note: There are 139 followers for the D7 patch of advagg #1171546: AdvAgg - D7 Port/Re-write → and over 1,600 users of AdvAgg.
I still believe using a database table for CSS/JS aggregates is the correct way to do this. Getting a lot of what AdvAgg does in core is going to take some work if we want to go that route.
A better HTTP client via HTTPRL is the first step (advagg generates the aggregates in the background (multiprocess php)). I'm pretty happy with what HTTPRL currently does so creating a core patch to incorporate it is where I would start (HTTPRL is born out of AdvAgg code). Next step is to make it plugable #64866-37: Pluggable architecture for drupal_http_request() → so different backends can be put in place if cURL is desired.
The current limitation that AdvAgg has is it doesn't take advantage of multi-sites. If we have the same CSS aggregate used across multiple sites on our server, taking advantage of that will make things a lot snappier (only need to generate one aggregate) and save disk space. This would require a global files folder, one that doesn't depend on the current site being accessed. Global storage of the old files that need to be deleted could be bypassed if we have a REST API for querying if the aggregate is old. This would require one site to be aware of all the other sites inside of the multi-site install so it knows what sites it should query via HTTP.
Once a better HTTP client is in core and (optional) a global files directory is available I might have the D7 version of AdvAgg done at which point we could create a patch for D8 core. This is my recommendation for core's CSS/JS aggregation. It's a big undertaking but a lot of what AdvAgg does is what we're trying to do. It uses the same codepath for both CSS and JS; S3/CDN friendly file-naming; caching for faster page generation times; etc... it does a lot, thus it would be a large patch. Gotta run...
- 🇺🇸United States effulgentsia
Once a better HTTP client is in core ... I might have the D7 version of AdvAgg done
Do we need the better HTTP client in core, or is the hack in #1664784: drupal_http_request() has problems, so allow it to be overridden → sufficient to unblock D7 AdvAgg? Please comment in that issue if more is needed there to satisfy AdvAgg.
at which point we could create a patch for D8 core
Are you recommending this as both the D7 and D8 solution, or D8 only? If D8 only, then is there any objection left to proceeding with an update of #47 for this issue, and doing #55 and/or AdvAgg in #352951: Make JS & CSS Preprocessing Pluggable → or a spin-off of that?
- 🇺🇸United States mikeytown2
D7 AdvAgg is not blocked; other than me needing time to do it. The D7 version of AdvAgg will rely on HTTPRL. Just stating that there is a lot going on.
This thread is for a D8 solution; back porting to 7x would be very hard to do. I've been working in #1447736: Adopt Guzzle library to replace drupal_http_request() → and in Comparison of HTTP Client Libraries. I've concluded that Guzzle is the way forward; it offers what we're looking for in a HTTP Client. For the one thing it was lacking at the time, Non Blocking Requests, the author made it happen. That's huge. If we come across other issues when integrating it it's nice to know that mtdowling is willing to help.
At the core of AdvAgg is a whole lot of hooks to make it pluggable and the ability to generate a CSS/JS file based off the filename.
My objection to #47 is everything is stored in a variable instead of a database table. Having things in 2 tables like I have in AdvAgg allow for thing like the bundler to work correctly and for smart aggregate flushing. #55 from my understating deals more with the mechanics of how the hook_menu of this works; which is covered in WSCCI.
I would be ok with #352951: Make JS & CSS Preprocessing Pluggable → , but I think shipping with something like AdvAgg (doesn't have to be AdvAgg) as the default would be good for the drupal community.
- 🇬🇧United Kingdom catch
To get around the filename length, we can keep a table with an autoincrement (or try to do something a bit niftier with hex or just any allowable filename character to have more to work with). Just mapping to files that have been added with drupal_add_*().
When files are added, we replace the filename with the ID. In the request that generates the aggregate, it can map the id back to the filename. This will be a lot less data to ship around than the current hashes when there's lots of aggregates and it should be possible to add lots and lots of files before getting anywhere near the limit.
- 🇬🇧United Kingdom catch
Also, for the DDOS issue, also spoke about this at some length with rupl, Mark Sonnabaum and greggles, and we've come up with a likely solution:
When the link to the aggregated CSS/JS is generated, we can hash the filenames + drupal_get_private_key(), and add that as a token to the request. The callback that assembles the aggregated file can then do the same and refuse to create the file if the token can't be validated.
- 🇫🇷France pounard
Here is what I actually do in the core_library module, this includes a SQL table too and is simpler IMO.
The table stores both the filenames array and hash along with a creation timestamp and a incremented version number.
Generated files are named hash-version so that older files are kept, ensuring that old caches somewhere (browser, proxy, etc...) will always have a resulting file in result, corresponding to the older cached page state.
Each time a CSS or JS file is modified, the creation timestamp raises, the table is updated with the increment set to +1 and the new creation time saved, resulting in a new CSS/JS file named hash-version+1. This way, one line only per aggregated "set" exists, but multiple versions coexist, and no filename lenght problem exist.
The hash is the table index, lookups are quite fast since the table won't massively grow on a production site.
The filename storage in a blob field allow two things, first as it is a blob, is supposedly not loaded into memory in caches by the SQL backend (depending on size and backend of course, I'm thinking about toasted columns in PgSQL) and also to fully rebuild the file on-demand when the URL is hit (no pre-aggregation is needed).
I came around a lot of thinking, and this is the best way I could find to manage those files, and it is efficient: the only drawback is the extra SQL query when either checking for version or building the file on first hit.
EDIT: Moreover with a bit of imagination the table could be replaced by any other backend easily (MongoDB, Redis, etc..) since there is one and only index/primary key which is the array hash.
- 🇬🇧United Kingdom catch
@pounard the post in #101 is missing some background.
If we try to support real subrequests in core, then we need a way for the actual page to be able to take assets added by those subrequests, put them into the header of the page, potentially aggregate them etc.
With real subrequests that logic can't happen in PHP (since potentially no PHP at all will be executed), so we'd need to either have a js loader that reads some embedded json and handles adding the assets, or apparently twig has some kind of mechanism for this too (not sure if twig handles the loader bit as well as the embedded assets bit at all). Either way this means being able to create an aggregate URL without writing out either files or to the database (assuming we don't want the loader making backend requests which I'm sure we don't), which makes a solution where all the information required to produce an actual aggregate is in the aggregate URL itself much more important. That provoked a lot of discussion at the Munich code sprint and led to trying to develop the 'filenames in the URL' approach to a point where it was both performant and secure.
- 🇫🇷France pounard
Now that hook_library_info() is mandatory for all JS and CSS, the whole system will become a lot more predictable, my opinion is that the aggregation mecanism should be tied to this hook data instead of trying to do anything dynamically. Using it may help us to do all of this without any database table or generated identifiers or hashes (althought I'm not fully convinced, but I think this path should be explored).
EDIT: This means that the system is a lot less dynamic now, and it may solve some of the subrequests problem.
- 🇺🇸United States yesct
#80: 1014086-80-css-imagecache.patch queued for re-testing.
The last submitted patch, 1014086-80-css-imagecache.patch, failed testing.
- 🇺🇸United States yesct
Is there any point in rerolling (http://drupal.org/patch/reroll) #80?
could use an issue summary update. tips to do: http://drupal.org/node/1427826
#886488-94: Add stampede protection for css and js aggregation → says this issue might help that one.
(the slash in the i/o tag breaks the autocomplete from adding new tags)
- 🇺🇸United States mikeytown2
Heads up, the D7 version of AdvAgg is now in beta. It stores the files and order used in the creation of the aggregate, the a hash of all the files content (versioning), and any setting that affects the output of an aggregate (CSS/JS minification, CDN settings, embedded images, http/https, etc). Also has stampede protection, backports D8 JS code, and is coded to reduce disk I/O.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
Now that #352951: Make JS & CSS Preprocessing Pluggable → has landed, I read the entire issue. Let's not fix everything here. For that, we have this meta issue: #1048316: [meta] CSS and Javascript aggregation improvement → .
Let's just fix the way CSS/JS aggregates are generated here, and implement the same strategy that we use for imagecache. (Taking into account the mistakes that were made for imagecache generation: https://drupal.org/SA-CORE-2013-002 — even though that is only superficially similar to the situation here.)
Thanks to #352951: Make JS & CSS Preprocessing Pluggable → , it will be much simpler for something like AdvAgg to be ported to Drupal 8. It'll be easy in Drupal 8 to implement any kind of aggregation logic.
But, for Drupal 8 core, with us having entered the post-API freeze period, I believe something like #101 might be the simplest possible approach:
When the link to the aggregated CSS/JS is generated, we can hash the filenames + drupal_get_private_key(), and add that as a token to the request. The callback that assembles the aggregated file can then do the same and refuse to create the file if the token can't be validated.
Let's get this going again!
- 🇬🇧United Kingdom catch
@Wim, #101 is only relevant if we also do #100.
There's two options really:
1. Store the aggregate filenames + list of files in state(), then the request that builds the file can reverse-lookup from the filename. This is what http://drupal.org/project/agrcache does and advcache is similar in that regard. The disadvantage with that approach is that this is a fairly large array to be fetching every request, and that whenever a new aggregate is requested, the main process has to write to state(). If the filename isn't found in state, nothing happens so there's no imagecache-esque DDOS vector.
2. Provide a representative of the filenames in the aggregate string itself (not the filename itself because that'd be too long). We map each individual file to a one or two character string ( in state()), then pass the list of tiny names in the filename (plus the hash), then the process generating the file can reverse lookup the filenames from the identifiers. This still requires a write to state in the parent process, but only when a new file is added (as opposed to new aggregate, so less frequent), and is a lot less data to be fetching from state() each request - just filename + two character string for each unique file, instead of aggregate filename + list of files for each unique aggregate. There's a bit of complexity added because you need to handle the shortest possible filenames (a-z/A-Z/_-/0-9) and ensure that you don't run out etc. but it ought to perform better.
If there's an option #3 someone please add it!
Regardless of #1 and #2, the route controller is going to look very similar, so unless there's a fatal flaw with one of the two approaches I'd be happy going with either for now, then we can swap it out if we decide the other was better later (or contrib can).
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
I think there might be an option #3… :)
It's inspired by https://docs.google.com/presentation/d/1Q44eWLI2qvZnmCF5oD2jCw-FFql9dYg3... — also see https://github.com/google/module-server for a sample implementation plus some more text.
So, the alternative proposal:
3. We have a dependency graph. We leverage that.
- Step 0: must finish the conversion to libraries.
- Step 1: revamp
drupalSettings.ajaxPageStateto list libraries, rather than specific CSS or JS files. - Step 2: define an aggregate by its filename, in which we list the "top-level libraries", which are libraries that are not a dependency of any of the other libraries on the page. So, we would never see an aggregate like
jquery,drupal,debounce,announce.js(because neither of those do anything in and of themselves, they're all merely utilities), instead we would just seecontextual.js, which implies that the "contextual" library plus all its dependencies are loaded. - Step 3: ensure that it works with multiple scopes, this is easy to do: if the header scope contains libraries foo and bar, and the footer contains libraries baz and qux, then the aggregate for the header would be
foo,bar.js, the aggregate for the footer would bebaz,qux-foo,bar.js: "libraries baz and qux plus their dependencies, minus libraries foo and bar and their dependencies". (This somewhat relates to #784626-59: Default all JS to the footer, allow asset libraries to force their JS to the header → .) - Step 4: ensure that it is regenerated whenever the contents change: the hash that we use for the aggregate's file name today can be embedded in the path: if the aforementioned aggregates would be generated at
some/path/aggregate/css/foo,bar.js, then we can do something likesome/path/aggregate/css/<uniqueness token>/foo,bar.js. This would also make it rather trivial for a contrib module to override things to generate that uniqueness token — cfr. ✨ Add a development mode to allow changes to be picked up even when CSS/JS aggregation is enabled Needs work . - Step 5: ensure we prevent DDoSsing: if the aforementioned aggregates would be generated at
some/path/aggregate/css/<uniqueness token>/foo,bar.js, then we can do something likesome/path/aggregate/css/<HMAC security token>/<uniqueness token>/foo,bar.js. This is exactly what the CDN module does today:$security_token = drupal_hmac_base64($uniqueness_token . $libraries_string, drupal_get_private_key() . drupal_get_hash_salt());.
- 🇬🇧United Kingdom catch
#114 looks like a good plan and I can't immediately think of any showstoppers.
- 🇫🇷France pounard
I see one small detail that could go wrong with #114: file names length will be proportional to the number of aggregated files, aside of that, it sounds OK.
I still think than using the state system for keeping track of aggregated files would be a rather good and failsafe solution instead of trying to dynamically lookup files names from the incoming URL.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
#116:
- It is true that the file name length will be proportional. But it won't be proportional to the number of aggregated files, only to the number of top-level libraries. That's a huge difference!
- I'm not sure if using the state system is so much better — as you already say, it requires the state to be tracked. And as we've seen earlier in this issue, that's a lot of state to track. Whereas for #114, there would be almost the exact same state tracking as we have today (or am I missing something?). Only when/if we do something like ✨ Add a development mode to allow changes to be picked up even when CSS/JS aggregation is enabled Needs work , we would need to track additional state.
- 🇬🇧United Kingdom catch
If we're passing a list of libraries comma-separated in the filename, then consulting hook_library_info() in the aggregate generation callback, then it may not be necessary to have any state tracking at all.
It's definitely a consideration whether there might be too many libraries in a scope and we run into file system limitations again, but then that only takes us back to #100 (or splicing the aggregate into two past a certain length would be another option then).
- 🇺🇸United States moshe weitzman Boston, MA
Any chance we can get this into d8?
- 🇺🇸United States dcrocks
Bump, and maybe related: #2260969: 404 error on css/js aggregated files in site located in a VirtualDocumentRoot → .
- 🇺🇸United States effulgentsia
This issue wouldn't fix #2260969: 404 error on css/js aggregated files in site located in a VirtualDocumentRoot → , since even if we deferred the file generation to a subsequent request, it would still happen eventually, at which point a misconfigured rewrite rule would still result in the same problem of failing to load a real file via its URL.
- 🇬🇧United Kingdom catch
Postponing on #2368797: Optimize ajaxPageState to keep Drupal 8 sites fast on high-latency networks, prevent CSS/JS aggregation from taking down sites and use HTTP GET for AJAX requests → since that'd mean we only have to deal with libraries.
- 🇺🇸United States yesct
putting the reason postponed in the issue summary.
- 🇬🇧United Kingdom catch
No longer postponed.
No way we can backport this to D7, but https://www.drupal.org/project/agrcache → and https://www.drupal.org/project/advagg → both do that in contrib.
- 🇬🇧United Kingdom catch
It'd potentially help our very worst cold cache performance (like the installer), so I wouldn't rule out doing it before 8.0.0.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
Oh, interesting, I didn't realize that. Cool :)
I think this is at least major.
- 🇬🇧United Kingdom catch
The reason it helps is that when aggregates don't exist, they have to be created inline during the same page request where they links to them are going to be rendered.
An action such as switching the default theme can mean both a theme registry rebuild and generation of a full set of asset aggregates within the same request (since it needs the theme-specific theme registry and the theme-specific asset bundles before the full page can be rendered).
Our very basic CSS minifier makes this quite expensive. I've seen agrcache save hundreds of milliseconds or more on client sites before. If we ever add inline minification of JavaScript in PHP it will be even more so and I'd consider this issue a blocker to enabling that in core at least by default.
With the approach here, each aggregate is created separately in a dedicated HTTP request, which doesn't block the (PHP) rendering of the page that they're linked from at all.
This also means that if lots of pages are requested at the same time, they can all render to HTML regardless of the asset generation happening, and then since assets are requested/generated in parallel (four aggregate requests might take 150ms each instead of 500ms for all four, say) there's less chance of apache connections getting backed up.
- 🇬🇧United Kingdom catch
Note that as well as cold cache performance, this will also save 3-4ms on warm caches as well. We lose two calls to state, and about 7 calls to file_exists() (profiling as user 1 with the standard profile).
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
We won't realistically get this done before RC1. Let's do this in 8.1.
- 🇺🇸United States mikeytown2
Quick note that this can cause a race condition if you're deploying code and have 3 or more webheads.
Request comes in on webserver #1 which has the new code; the request for the css file hits webserver #3 which has the old code; file gets generated with the old code. In rare circumstances this can result in a zero byte aggregate being created (new file deployed, which is the only file iin the aggregate).
- 🇬🇧United Kingdom catch
@mikeytown2 I ran into that with agrcache, see #2628918: Address deployment race conditions → .
It's not just about code mismatches (although it can be), it's also file_unmanaged_save_data() not being atomic.
Drupal 8.1.0-beta1 → was released on March 2, 2016, which means new developments and disruptive changes should now be targeted against the 8.2.x-dev branch. For more information see the Drupal 8 minor version schedule → and the Allowed changes during the Drupal 8 release cycle → .
- 🇺🇸United States mikeytown2
I have a lot of extra code in advagg to handle the fact that file_unmanaged_save_data is not atomic, thanks for the tip! http://cgit.drupalcode.org/advagg/tree/advagg.missing.inc#n979
In terms of deployments it looks like we both came to the same conclusion; do the best that we can, but don't write the file (I still need to make this happen).
- 🇬🇧United Kingdom catch
I've been working on agrcache a bit again recently, mostly around fixing the race condition mentioned in #135, so started taking a look at what it would take to get this issue done.
While agrcache doesn't have a massive user base, it's used on some very high traffic/complex sites, and every bug it's run into since January 2011 (!) that's relevant to this issue has been fixed by this point. Functionally it does everything we'd need to do here, except the 8.x port and using libraries as URLs rather than the hash (not that those are small, they're the main reason this hasn't happened since it was opened, but a lot of issues that only appear on high traffic production environments are well covered).
Note that #114 covers #135 to a large extent already, assuming we validate the hash before writing anything out. If we include the HMAC for DDOS protection, we'd need to only HMAC against known libraries, not against the specific uniqueness hash, since that will be based on the code base at the time. Also we should not throw 500s or 503s in that case - just probably an empty file, 200 and log since the ability to trigger 500s can itself be a DDOS vector depending on load balancer configuration.
There are a couple of things that are missing from our current plan in #114 that need sorting out:
1. We support the 'browsers' option for both CSS and JavaScript which is translated to conditional comments. We'd need to ensure those still get rendered separately, and not via the library aggregates. That's going to add some complexity, but not insurmountable.
What's missing from #114 is handling of the 'browsers' option, which we support for both CSS and JavaScript. IE10 dropped support for conditional comments, so we can drop that when we drop support for IE9.
2. This reminded me we still have special handling for the 31 stylesheets limit in IE, that we also can't drop until we drop support for IE9, it should not affect things here but just noting.
- 🇬🇧United Kingdom catch
Extra things here that are still a problem:
1. We still have weights
2. Wim confirmed we still have aggregate groups.
That makes library-based URLs considerably harder, since the combination of weights, groups and browsers can result in aggregates getting arbitrarily split up.
- 🇬🇧United Kingdom catch
Here's an initial patch. Also updating the issue summary.
Not ready for a nitpick review, but needs architectural review before adding js into this. Also didn't really look at test coverage yet, I have a feeling none of this is actually tested but we'll find out.
I've solved all the issues in #139 and #140 afaik, but this required taking a slightly different approach with the filenames and overall logic. It's not a massive diversion but took a bit of thought.
The last submitted patch, 142: 1014086-140.patch, failed testing.
The last submitted patch, 144: 1014086-144.patch, failed testing.
The last submitted patch, 144: 1014086-144.patch, failed testing.
- 🇬🇧United Kingdom catch
Started some profiling, profiling found some issues so here's an updated working patch, still only for CSS. Will upload profiling results in a bit.
Our interfaces for this stuff are very coupled to the current logic, which is a shame.
The last submitted patch, 148: 2664274-147.patch, failed testing.
- 🇬🇧United Kingdom catch
Here's a couple of xhprof screenshots with the patch.
I got this by doing the following (standard profile + user 1)
1. warm caches
2. rm -f sites/default/files/css/*
3. DELETE FROM cache_data WHERE cid LIKE 'css%';That gets a cache miss on css asset resolving and the file creation itself, but nothing else.
One shows AssetResolver::getCssAssets() - this now only does enough work to generate the filename.
The other shows CssAssetController::deliver() - this is now getting the file contents, optimizing, and writing out to the file including gzipping for a single asset group. There's five on the front page.
CssAssetController::deliver() is taking about 50ms for the group, since there are 5 groups on the front page by default, that's easily 250ms.
AssetResolver:getCssAssets() now takes 13ms for all groups.
So that's a saving of around 230ms for a cold cache on the standard profile for the main request.
In terms of a cold cache situation, this should mean that:
1. The page renders about 215ms faster.
2. The CSS files take about 200ms to render (since a lot happens serving the request other than building and writing the aggregate)So the page won't actually render faster overall, but time to first byte is much quicker, but the main page doesn't block on creating the aggregates, other requests aren't blocked on creating the aggregates, and none of the individual CSS files block loading of the others.
The last submitted patch, 147: 1014086-144.patch, failed testing.
The last submitted patch, 151: 1014086-151.patch, failed testing.
- 🇬🇧United Kingdom catch
Not really trying to get tests to pass yet, but removing one hunk of stupidity...
- 🇬🇧United Kingdom catch
OK the main things that need discussion:
1. The 'group delta' and hash are in the filenames to identify which file to create. That lets us keep filenames themselves short.
2. On the other hand, the libraries are needed too, but put these into query parameters since they'd result in very long filenames otherwise. With both CSS and JavaScript we only need to send the leafs of dependency trees. But especially CSS from themes etc. we don't really declare dependencies much,so these risk breaking the 2000-ish character limit for $_GET requests on IE. See https://blogs.msdn.microsoft.com/ieinternals/2014/08/13/url-length-limits/ and http://stackoverflow.com/questions/417142/what-is-the-maximum-length-of-...
If we think we're going to run into the 2000 character limit, we could potentially workaround this, but it'll be ugly.
3. This hashes by asset definitions (minus weight since core still changes that unpredictably) instead of file contents. It would be feasible to hash by (pre-optimized) file contents since the URL generation in the main request is cached (without maintaining a state entry still), although of course makes that more expensive, and it will happen whether the aggregate exists or not when caches are cleared. I switched agrcache to this recently, but only because it doesn't have 8.x's library versioning. With library versioning, I think hashing by the info is enough.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
I like it overall, but I think improved/clearer documentation explaining the overall flow would be very helpful.
In a nutshell: the CSS collection optimizer still does what it is supposed to do: given a collection of assets, return URIs to optimized assets. The only difference is that those optimized asset URIs don't have corresponding files on disk yet, they're lazily built.
I think it's worthwhile to continue in the direction of this patch.
But especially CSS from themes etc. we don't really declare dependencies much
Great, then this is an excellent incentive to encourage that. Also, I'm not really concerned about this. Because many (most?) themes actually will have one asset library with all the CSS. No dependencies, but also just one library. So it really won't cause us to approach that 2K limit.
With library versioning, I think hashing by the info is enough.
Yes, assuming that asset library versions are sane/working well. They're currently not. See #2205027: VERSION in library declarations does not work for contributed/custom modules → .
-
+++ b/core/modules/system/src/Controller/CssAssetController.php @@ -0,0 +1,274 @@ + $libraries = $this->libraryDependencyResolver->getLibrariesWithDependencies($request->query->get('libraries'));Probably can use a comment to indicate why this is safe.
-
+++ b/core/modules/system/src/Controller/CssAssetController.php @@ -0,0 +1,274 @@ + throw new BadRequestHttpException('Invalid filename'); ... + throw new BadRequestHttpException('Invalid filename'); ... + throw new BadRequestHttpException('Invalid filename'); ... + throw new BadRequestHttpException('Invalid filename');Do we want more meaningful error messages?
-
+++ b/core/modules/system/src/Controller/CssAssetController.php @@ -0,0 +1,274 @@ + // A non-matching hash does not necessarily mean a bad request, it could + // also mean that code is temporarily out of sync between different servers.Can use a comment explaining why this is ok/how this will automatically recover.
-
+++ b/core/modules/system/src/Controller/CssAssetController.php @@ -0,0 +1,274 @@ + 'Cache-control' => 'private, no-store',Why? To avoid Page Cache from storing it? For the end user, this is (and should be!) cacheable.
If my suspicion is correct, then let's do
no_cache: TRUEon the route, and not this. -
+++ b/core/modules/system/src/Routing/AssetRoutes.php @@ -0,0 +1,71 @@ + $routes['system.css_asset'] = new Route( + '/' . $directory_path . '/css/{file_name}',We'll need a test to verify that if you change the configuration of the public files directory path, that the routes are rebuilt also.
-
- 🇬🇧United Kingdom catch
Thanks for the review!
If you're not concerned about the 2k limit, nor am I.
#4
Why? To avoid Page Cache from storing it? For the end user, this is (and should be!) cacheable.
This is mostly for reverse proxies/CDNs, but partly for end-users too. The headers from a PHP request will never, ever be the exactly the same as the headers for a file served from disk.
So if we send cacheable headers, then should any of those headers have a material effect (content encoding, max_age etc. potentially could), you can get extremely hard to track down bug reports which are only reproducible for a certain subset of users. For example one CDN endpoint could have the PHP request in cache, the other could have the file request cached.
The specific case I ran into is still a @todo here, or more likely should have a follow-up/pre-requisite issue to track it. file_unmanaged_save_data() uses cp which is not atomic. This in turn means that a PHP request could read a half-saved (i.e. empty) file from disk, then serve it with cacheable headers. So some people would get empty CSS or JS files, others they'd be fine, depending on the CDN endpoint. #2628918: Address deployment race conditions → was the agrcache issue, with agrcache_file_unmanaged_save_data() having most of the info.
We'll need a test to verify that if you change the configuration of the public files directory path, that the routes are rebuilt also.
Pretty sure that image module, which is where I copied this from, does not do this at all. We don't in reality support changing the public files directory via a configuration change (i.e. you need to manually move it on disk, and would also have to clear the entire render cache in case there's linked files in it, and rebuild the routes for image module). https://www.drupal.org/upgrade/file_public_path → made it not configurable from the UI. So not sure a reasonable test can be written without additionally fixing some of those issues.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
So if we send cacheable headers, then should any of those headers have a material effect (content encoding, max_age etc. potentially could), you can get extremely hard to track down bug reports which are only reproducible for a certain subset of users. For example one CDN endpoint could have the PHP request in cache, the other could have the file request cached.
This is full of important insights, please add it as a comment to the code :)
Pretty sure that image module, which is where I copied this from, does not do this at all. We don't in reality support changing the public files directory via a configuration change […] So not sure a reasonable test can be written without additionally fixing some of those issues.
Ok, that's reasonable. Then let's create an issue that adds test coverage for that case for the image module, and let's let this refer to that issue too. Then we avoid future surprises.
- 🇬🇧United Kingdom catch
Opened #2688389: file_unmanaged_save_data()/file_unmanaged_move() are not atomic → .
On the image module/public:// issue. I just realised we actually moved this completely to $settings, not just out of the UI. Since simpletest itself installs with a public path that is not sites/default/files, then we have implicit coverage of this, and not sure explicit coverage will add anything at all. I was going to open an issue, but realised that when I started typing it up. If you think there's something more we can do please add though - this is a very murky area in general.
- 🇺🇸United States mikeytown2
Also see #1377740: file_unmanaged_move() should issue rename() where possible instead of copy() & unlink() → and #818818: Race Condition when using file_save_data FILE_EXISTS_REPLACE → .
In terms of headers being different I don't think it's that big of a deal. Here is my handler for sending out a request from AdvAgg http://cgit.drupalcode.org/advagg/tree/advagg.missing.inc#n195.
Not sure if this is an issue in D8 but in D7 drupal_tempnam() does not pass along the subdir if using a stream wrapper. Here's the code from AdvAgg to handle this situation
// Corect the bug with drupal_tempnam where it doesn't pass subdirs to // tempnam() if the dir is a stream wrapper. $scheme = file_uri_scheme($uri_dir); if ($scheme && file_stream_wrapper_valid_scheme($scheme)) { $wrapper = file_stream_wrapper_get_instance_by_scheme($scheme); $dir = $wrapper->getDirectoryPath() . '/' . substr($uri_dir, strlen($scheme . '://')); $uri = $dir . substr($uri, strlen($uri_dir)); } else { $dir = $uri_dir; }You'll want to write to a temp file in the target dir first before renaming so this will need to be fixed as well.
- 🇬🇧United Kingdom catch
Based on every site I've worked on since 2010 that uses core's aggregation going down due to it at some point until they switched to either advagg or agrcache, upgrading this to a bug report.
The patch on #1377740-87: file_unmanaged_move() should issue rename() where possible instead of copy() & unlink() → is green, so can probably continue here. Someone in irc ran into the file_unmanaged_save_data() issue with core aggregation, so that's a separate bug really.
- 🇬🇧United Kingdom catch
Here's some improved comments.
@Wim if that looks good, I'll start working on the js version.
The last submitted patch, 165: 1014086-165.patch, failed testing.
Drupal 8.2.0-beta1 → was released on August 3, 2016, which means new developments and disruptive changes should now be targeted against the 8.3.x-dev branch. For more information see the Drupal 8 minor version schedule → and the Allowed changes during the Drupal 8 release cycle → .
- 🇩🇪Germany Fabianx
+++ b/core/modules/system/src/Controller/CssAssetController.php @@ -0,0 +1,282 @@ + 'Cache-control' => 'private, no-store',We will need to put this headers into a helper function / service or configurable via the container or settings.
Also I really think we should add Edge-Control: bypass-cache if we go to the lengths here or at least give an akamai-8.x module a change to influence those headers ... (if we don't want to add proprietary headers)
--
Overall looks like a great start to me! Needs some more work obviously ...
The last submitted patch, 172: 1014086.patch, failed testing.
- 🇬🇧United Kingdom catch
Untested patch to add javascript support. Added a base class for the controllers.
The last submitted patch, 175: 1014086-175.patch, failed testing.
The last submitted patch, 176: 1014086-176.patch, failed testing.
The last submitted patch, 179: 1014086-179.patch, failed testing.
The last submitted patch, 181: 1014086-180.patch, failed testing.
- 🇩🇪Germany dawehner
Just some quick feedback, so that catch doesn't feel alone on this issue.
I really like the problems it fixes, like stale CSS files during the deployment.
-
+++ b/core/lib/Drupal/Core/Asset/AssetResolver.php @@ -118,7 +118,24 @@ public function getCssAssets(AttachedAssetsInterface $assets, $optimize) { + $css = \Drupal::service('asset.css.collection_optimizer')->optimize($css);Let's ensure to inject the service
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -141,6 +101,21 @@ public function optimize(array $css_assets) { + foreach ($css_assets as $order => $css_asset) { ... + $theme_name = $this->themeManager->getActiveTheme()->getName(); + $query = UrlHelper::buildQuery(['libraries' => $minimal_set, 'theme' => $theme_name]);This query seems to be the same across the entire foreach
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -155,11 +130,13 @@ public function optimize(array $css_assets) { protected function generateHash(array $css_group) { - $css_data = array(); - foreach ($css_group['items'] as $css_file) { - $css_data[] = $css_file['data']; + $normalized = $css_group; + foreach ($normalized as $order => $group) { + foreach ($group['items'] as $key => $asset) { + unset($normalized[$order]['items'][$key]['weight']); + } } - return hash('sha256', serialize($css_data)); + return hash('sha256', serialize($normalized));Does the same problem exist for the JS one as well?
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,287 @@ + $base_name = basename($file_name, '.' . $this->fileExtension); + + $file_parts = explode('_', $base_name); + // The group delta is the second segment of the filename, if it's not there + // then the filename is invalid. + if (!isset($file_parts[1]) || !is_numeric($file_parts[1])) { + throw new BadRequestHttpException('Invalid filename'); + } + $group_delta = $file_parts[1]; + + // The hash is the third segment of the filename. + if (!isset($file_parts[2])) { + throw new BadRequestHttpException('Invalid filename'); + } + $hash = $file_parts[2]; + + // If the group being requested does not exist, assume an invalid filename. + if (!isset($groups[$group_delta])) { + throw new BadRequestHttpException('Invalid filename'); + } + $group = $groups[$group_delta]; + + // Only groups that are preprocessed will be requested, so don't try to + // process ones that aren't. + if (!$group['preprocess']) { + throw new BadRequestHttpException('Invalid filename'); + }Some of them (2) seem to not depend on the previous calculations
-
- 🇬🇧United Kingdom catch
#1: this was just moved in the patch, but switched to injected.
#2: fixed, and some similar bits.
#3: yes same problem, updated the docs and variable namings. This is the same issue as #721400: Order JS files according to weight, don't change filenames for aggregated JS/CSS → and related to #1388546: Adding CSS or JS files twice changes weight → - both fixed in 8.x, but without this code would be re-introduced.
#4: some of those conditions can be combined.
Working on a patch for these, but also found massive bugs in the js implementation (not surprising, just things not ported from the current logic yet), so assigning to self and marking CNW.
- 🇬🇧United Kingdom catch
OK this one works with (minimal) manual testing for both CSS and JavaScript, I didn't run any tests yet so those could still blow up, but functionally and conceptually should be close now.
Couple of things I realised when working on js, the first was a pre-existing bug for CSS too, the second is js-specific:
1. We now pass both $libraries and $already_loaded as query parameters. This is because we reduce the libraries needed to minimally representative set, then get their dependencies in the controller. But once we've got their dependencies, we have no idea if they were already loaded on that page. So I'm setting already_loaded_libraries when $ajax_page_state is available (which is the only time core uses it apart from big_pipe).
2. Due to JavaScript scope, there are actually two group sets of asset groups on a page. So i had to add scope to the query string for js in order to be able to get the header group or the footer group to then fetch our asset group from, otherwise with only a $group_delta it could be in either.
Otherwise the js implementation is essentially the same as the CSS one.
I was also able to remove a method I'd added to AssetResolver, which keeps that interface intact.
There's still an extra (optional) argument added to AssetDumperInterface - this needs discussion. We could add a new interface for backwards compatibility if we have to with a new method taking the extra parameter. I know advagg implements these interfaces in contrib, but really doubt anything else does in 8.x (magic isn't ported, my own asset modules also aren't ported and won't be assuming this lands eventually).
Even if this passes there's going to be some rough edges, and haven't looked at the test coverage yet. Now that the actual preprocessing is done in the controller, it makes the asset classes a bit cleaner and more testable if anything, but we really need a test that renders a page with css + js aggregation on, visits the URLs directly and makes sure it gets something valid back or similar - afaik there isn't such a test in core.
The last submitted patch, 187: 1014086-187.patch, failed testing.
- 🇬🇧United Kingdom catch
Should resolve at least some of the test failures. Also factored out the hashing into a trait.
The last submitted patch, 190: 1014086-190.patch, failed testing.
- 🇬🇧United Kingdom catch
Should fix a few more - js settings are tricky is the tl;dr.
The last submitted patch, 192: 1014086-192.patch, failed testing.
- 🇬🇧United Kingdom catch
5.5 fail was segfault in migrate tests, don't think that's this patch so back to CNR.
- 🇬🇧United Kingdom catch
New patch adds new AssetDumperUriInterface to avoid changing the original one.
Other bits of clean-up too.
The last submitted patch, 195: 1014086-195.patch, failed testing.
The last submitted patch, 196: 1014086-196.patch, failed testing.
- 🇩🇪Germany Fabianx
Overall the patch looks great.
One thing I wondered:
Do we want to make this the default and remove / deprecate the old ways or do we want to keep the old code around and refactor it a little, so that by nice sub-classing we can provide both ways.
Given how critical this is, it might be prudent to allow via configuration to switch back to the old way.
- 🇬🇧United Kingdom catch
Thanks Fabian.
I've thought about providing new classes rather than changing the old ones, not opposed to doing that.
Bit of self-review of the patch. Will fix these in next update.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionGrouper.php @@ -45,6 +45,9 @@ public function group(array $js_assets) { break; + default: + $e = new \Exception(); + trigger_error($e->getTraceAsString()); }debug.
-
+++ b/core/modules/system/src/Controller/CssAssetController.php @@ -0,0 +1,74 @@ + public function __construct($library_dependency_resolver, $asset_resolver, $theme_initialization, $theme_manager, $grouper, $optimizer, $dumper) {Missing type hints.
-
+++ b/core/modules/system/src/Controller/CssAssetController.php @@ -0,0 +1,74 @@ + protected function optimize($group) { + // Optimize each asset within the group. + $data = ''; + foreach ($group['items'] as $asset) { + $data .= $this->optimizer->optimize($asset); + } + // Per the W3C specification at + // http://www.w3.org/TR/REC-CSS2/cascade.html#at-import, @import + // rules must precede any other style, so we move those to the + // top. + $regexp = '/@import[^;]+;/i'; + preg_match_all($regexp, $data, $matches); + $data = preg_replace($regexp, '', $data); + return implode('', $matches[0]) . $data; + }This ought to be calling the css collection optimizer - which means a new interface with a new method for collection optimizers.
-
+++ b/core/modules/system/src/Controller/JsAssetController.php @@ -0,0 +1,90 @@ + /** + * {@inheritdoc} + */ + protected function optimize($group) { + $data = ''; + foreach ($group['items'] as $js_asset) { + // Optimize this JS file, but only if it's not yet minified. + if (isset($js_asset['minified']) && $js_asset['minified']) { + $data .= file_get_contents($js_asset['data']); + } + else { + $data .= $this->optimizer->optimize($js_asset); + } + // Append a ';' and a newline after each JS file to prevent them + // from running together. + $data .= ";\n"; + } + // Remove unwanted JS code that cause issues. + return $this->optimizer->clean($data); + }Same here - move logic back to an optimizer.
-
- 🇬🇧United Kingdom catch
This fixes #202 but not #201 yet. However if it's green, then it should be a clean-ish starting point to work on #201 from.
The last submitted patch, 203: 1014086-203.patch, failed testing.
- 🇬🇧United Kingdom catch
OK now covers #201.
The internally bc-incompatible changes are in CssCollectionOptimizer and JsCollectionOptimizer, so I did the following:
1. Copied the new implementations to CssCollectionOptimizerLazy and JsCollectionOptimizerLazy (and updated the service definitions to point to those classes).
2. Created new CssCollectionOptimizerTrait and JsCollectionOptimizerTrait with optimizeGroup() and deleteAll() methods.
3. Use those methods in both the new and old classes.
The optimize() method is different in both, there's a few lines of shared code but it's less than 50% of the method, don't see a nice way to share any of it.
While in there I also @deprecated AssetCollectionOptimizerInterface::getAll() since it's both pointless and impossible to implement correctly.
I don't think anyone should use these classes, so I @deprecated them, but this does mean that if someone was subclassing them, their subclass should still work - we don't have to do that but it doesn't hurt.
The last submitted patch, 206: 1014086-206.patch, failed testing.
- 🇬🇧United Kingdom catch
Found some issues with hashing/filenames in manual testing. I think we need a test that finds all the css/js aggregates on a page, then explicitly visits the URLs and checks we get something reasonable back.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
#187:
But once we've got their dependencies, we have no idea if they were already loaded on that page.
If that's the case, then it's because we overlooked something, and then this is a great catch. I thought we addressed that problem, but I might be mistaken. I thought we used the "fully resolved/expanded set of libraries", both in terms of what is needed and what is already loaded, then diffed, and then reduced it to the minimally representative set.
If that's not how it works, then we probably need more test coverage for that too.
Are you very certain that it's a pre-existing bug for CSS though?
getMinimalRepresentativeSubset()is only called in one place: insystem_js_settings_build(), it's not used in CSS asset handling at all.we really need a test that renders a page with css + js aggregation on, visits the URLs directly and makes sure it gets something valid back or similar - afaik there isn’t such a test in core.
Indeed, test coverage for asset aggregation has always been weak. #352951: Make JS & CSS Preprocessing Pluggable → significantly expanded it though. But it's all unit test, not integration test. This patch of course increases the need for an integration test, because aggregates are now lazily built.
#201:
Do we want to make this the default and remove / deprecate the old ways or do we want to keep the old code around and refactor it a little, so that by nice sub-classing we can provide both ways.
I'd personally instead favor removing the old way early in the 8.3 cycle. Then this new method will be tested all throughout the 8.3 development cycle.
Maintaining both seems a nightmare. As long as we don't break BC, there's no reason to keep the old way AFAICT. Or is there? (Of course, we should keep the classes around for those that have been subclassing.)
(It's not like HEAD's aggregation handling is not without bugs: there are lots and lots of issues, many of which have been open for years.)
#206:
While in there I also @deprecated AssetCollectionOptimizerInterface::getAll() since it’s both pointless and impossible to implement correctly.
I'm very concerned about that. We need that, for #2258313: Add license information to aggregated assets → . This is why asset libraries must declare their license in Drupal 8. See https://www.drupal.org/node/2307387 → .
Patch review!
-
+++ b/core/lib/Drupal/Core/Asset/AssetCollectionGroupOptimizerInterface.php @@ -0,0 +1,20 @@ +/** + * Interface defining a service that optimizes a collection of assets. + */ +interface AssetCollectionGroupOptimizerInterface extends AssetCollectionOptimizerInterface { ... + public function optimizeGroup(array $group);I'm not convinced we need this.
If we need this, then I'm not sure it extending
AssetCollectionoptimizerInterfacemakes sense.Either you have a single asset, or you have a group of assets, or you have a collection. It's a hierarchy: asset in a group in a collection.
Hence this interface extending that other one makes little sense to me.
(Related: [#2034675])
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,128 @@ + * Constructs a CssCollectionOptimizer.Nit: Mismatch.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,128 @@ + * The Theme manager.Nit: s/Theme/theme/
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,128 @@ + // To reproduce the full context of assets outside of the request, + // we must know the entire set of libraries used to generate all CSS + // groups, whether or not files in a group are from a particular + // library or not. + foreach ($css_group['items'] as $css_asset) { + $libraries[$css_asset['library']] = $css_asset['library'];Ahh, this is why :)
I wonder if this means we should prefix
'library'with'_library', otherwise developers could set this in their library definitions too. That could be confusing. -
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,128 @@ + // done by \Drupal\system\controller\CssAssetControllerNit: missing trialing period.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,128 @@ + $minimal_set = \Drupal::service('library.dependency_resolver')->getMinimalRepresentativeSubset($libraries); ... + $ajax_page_state = \Drupal::request()->get('ajax_page_state'); ... + $minimal_already_loaded_set = \Drupal::service('library.dependency_resolver')->getMinimalRepresentativeSubset($already_loaded);These need to be injected.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,128 @@ + $query = UrlHelper::buildQuery(['libraries' => $minimal_set, 'theme' => $theme_name, 'already_loaded' => $minimal_already_loaded_set]);Can we format this across multiple lines?
Then we can also make the code a bit more legible:
'theme' => $this->themeManager->getActiveTheme()->getName(),etc.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,128 @@ + // Create the css/ or js/ path within the files folder.Comment mentions JS.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,128 @@ + $path = 'public://' . 'css';Nit: this can be concatenated already.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,128 @@ + // Generate a URL for the group, but do not process it inline, this isThis says "for the group", but this code is outside of the for-loop, so it applies not just to a single group, but to the entire collection.
Which makes me wonder whether this actually works :P AFAICT this will only ever generate a single preprocessed asset.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,130 @@ + * Constructs a JsCollectionOptimizer.Similar mismatch.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,130 @@ + * The theme manger.Nit: s/manger/manager
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,130 @@ + * The grouper for JS assets.Nit: s/The/A/ (or otherwise change the CSS one to match this)
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,130 @@ + // Generate a URL for the group, but do not process it inline, this is + // done by \Drupal\system\controller\JsAssetController + $minimal_set = \Drupal::service('library.dependency_resolver')->getMinimalRepresentativeSubset($libraries); + $theme_name = $this->themeManager->getActiveTheme()->getName(); + $ajax_page_state = \Drupal::request()->get('ajax_page_state'); + $already_loaded = isset($ajax_page_state) ? explode(',', $ajax_page_state['libraries']) : []; + $minimal_already_loaded_set = \Drupal::service('library.dependency_resolver')->getMinimalRepresentativeSubset($already_loaded); + $header_query = UrlHelper::buildQuery(['libraries' => $minimal_set, 'theme' => $theme_name, 'already_loaded' => $minimal_already_loaded_set, 'scope' => 'header']); + $footer_query = UrlHelper::buildQuery(['libraries' => $minimal_set, 'theme' => $theme_name, 'already_loaded' => $minimal_already_loaded_set, 'scope' => 'footer']); + $path = 'public://' . 'js';Same remarks here.
-
+++ b/core/lib/Drupal/Core/Asset/AssetResolver.php @@ -148,6 +148,7 @@ public function getCssAssets(AttachedAssetsInterface $assets, $optimize) { + $options['library'] = $library; @@ -264,6 +265,7 @@ public function getJsAssets(AttachedAssetsInterface $assets, $optimize) { + $options['library'] = $library;Interesting, but not sure why yet.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + * Constructs a CssAssetController object.Nit: mismatch.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + * The library dependency resolver.Nit: one leading space too many.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + * The Asset resolver.Nit: s/Asset/asset/
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + * Generates a CSS aggregate, given a filename.s/CSS//
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + * The transferred file as response or some error response.This doesn't generate error responses; it throws
*HttpExceptions in those cases. -
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + public function deliver(Request $request, $file_name) { ... + $file_parts = explode('_', basename($file_name, '.' . $this->fileExtension)); + // The group delta is the second segment of the filename and the hash is the + // third segment. If either are not there, then the filename is invalid. + if (!isset($file_parts[1]) || !is_numeric($file_parts[1]) || !isset($file_parts[2])) { + throw new BadRequestHttpException('Invalid filename'); + } +++ b/core/modules/system/src/Routing/AssetRoutes.php @@ -0,0 +1,80 @@ + '/' . $directory_path . '/js/{file_name}',Huh, how did you get this
$file_name/{file_name}parameter to work? That's "D6/D7 menu tail-like" functionality, and that doesn't work in my experience in D8. See\Drupal\image\PathProcessor\PathProcessorImageStylesfor how that was solved for serving image styles. -
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + // 2. Someone has requrested an outdated URL during a deployment. This isNit: s/requrested/requested/
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + // key to create an HMAC, so that only valid combinations of libraries are + // allowed.What is "a valid combination of libraries"?
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + // For now treat all of these the same, but if there’s no match, don’t write + // to the filesystem. + $match = TRUE;Hmmm… doesn't that mean malicious users are still able to perform DoS attacks?
Can't we use a less specific hash in the URL, one that omits the specific weights and CSS files, and instead only cares about the set of asset libraries and a particular group?
Then you can have graceful degradation, because the set of asset libraries rarely changes. Groups change more often, but if a group is empty after a deployment, then fine, you return an empty aggregate file. Once cached HTML responses disappear, requests for such an empty aggregate would disappear.
-
+++ b/core/modules/system/src/Routing/AssetRoutes.php @@ -0,0 +1,80 @@ +/** + * @file + * Contains \Drupal\system\Routing\AssetRoutes. + */Nit: delete.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + 'Content-Type' => $this->contentType,You don't need any of this,
BinaryFileResponsedoes this automatically. -
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + // Headers sent from PHP can never perfectly match those sent when the + // file is served by the filesystem, so ensure this request does not get + // cached in either the browser or reverse proxies. Subsequent requests + // for the file will be served from disk and be cached. This is done to + // avoid situations such as where one CDN endpoint is serving a version + // cached from PHP, while another is serving a version cached from disk. + // Should there be any discrepancy in behaviour between those files, this + // can make debugging very difficult. + 'Cache-control' => $this->cacheControl,This results in
private, no-storebeing sent always, thus preventing aggregates from being cached. Looks like an oversight. -
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + $headers = [ + 'Content-Type' => $this->contentType, + 'Cache-control' => $this->cacheControl, + ]; + // Generate response. + $response = new Response($data, 200, $headers); + return $response; + } + else { + return new BinaryFileResponse($uri, 200, $headers);Why this if/else? Why not just generate the file if it doesn't exist, and then always use
BinaryFileResponse?Also, you should do
$response->isNotModified($request);. This ensures a304is sent if the file is not modified since last time. -
+++ b/core/modules/system/src/Controller/JsAssetController.php @@ -0,0 +1,61 @@ + $assets = $scope == 'header' ? $js_assets_header : $js_assets_footer;Let's use strict equality.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + * The Asset Resolver. ... + * The Theme Initialization.Nit: We don't do this capitalization.
-
- 🇬🇧United Kingdom catch
Just responding to things that need discussion, the rest I'll try to fix in next update:
I thought we used the "fully resolved/expanded set of libraries", both in terms of what is needed and what is already loaded, then diffed, and then reduced it to the minimally representative set.
I have two libraries:
Library A - depends on jQuery
Library B - depends on jQuery.
The minimally representative set of library B doesn't mention jQuery, when I expand it to include dependencies, it does - how do I know, only given library B as a query parameter, that jQuery has already been loaded?
This is all about the information passed to the new controllers - I wasn't able to find a bug in core, just figured out we need to compare the requested vs. loaded libraries in the controller.
The other way to do it would be to pass the full list of needed libraries to the controller, and not resolve dependencies there, but that's likely to be a longer list IMO so I went for passing both lists, since the second list will be empty in 99.99% of cases, meaning shorter URLs most of the time.
I'd personally instead favor removing the old way early in the 8.3 cycle. Then this new method will be tested all throughout the 8.3 development cycle.
Maintaining both seems a nightmare. As long as we don't break BC, there's no reason to keep the old way AFAICT. Or is there? (Of course, we should keep the classes around for those that have been subclassing.)
The most recent patch leaves the old classes in place (in case someone's subclassing and relies on the behaviour of the methods - i.e. if you call CssCollectionOptimizer::optimize() right now it writes to a file, but it won't after the patch). It's not clear from your comment which of these you prefer. Both patches switch to using the new way - you'd have to override the service entries in the container to use the old way again. I think this is reasonable for bc and there's not that much code duplication from leaving the old classes around. However I don't want to test those old classes...
I'm very concerned about that. We need that, for #2258313: Implement JS Web License Labels to allow for JS minification. This is why asset libraries must declare their license in Drupal 8.
It would be possible to re-add the state service and write to it when we write a file (in the controller or the dumper), however it would only be used to provide a list, not useful for anything else. This patch could add it, but then we're writing to state for no reason, or that patch could add it in - since it changes the information written to state slightly anyway?.
I'm not convinced we need this.
If we need this, then I'm not sure it extending AssetCollectionoptimizerInterface makes sense.
Either you have a single asset, or you have a group of assets, or you have a collection. It's a hierarchy: asset in a group in a collection.
Hence this interface extending that other one makes little sense to me.
We need it so that the controller can call that method on the service. It's also used to share code with the old class.
The interface extends the old one just to avoid a bc break. Right now the methods on these classes are very long and do too many things IMO - this takes a specific bit of logic and makes it re-usable. Ideally we'd deprecated the old interface and just use this new one eventually - then in 9.x rename it back. Interested what you think. Another option would be an entirely new service and interface that just does this and nothing else, but that could be too granular then?
These need to be injected.
They're not injected in the existing classes, this is just copied, but yes we can improve that.
Huh, how did you get this $file_name/{file_name} parameter to work? That's "D6/D7 menu tail-like" functionality, and that doesn't work in my experience in D8. See \Drupal\image\PathProcessor\PathProcessorImageStyles for how that was solved for serving image styles.
There's a route for css and a route for js, and two different controllers, the only parameter is the file name.
Hmmm… doesn't that mean malicious users are still able to perform DoS attacks?
Um, not really? They can make a request that will always hit PHP, but it'll take less than a normal uncached page render would, and not write to the disk. If they were able to write to the disk, then I'd be concerned about DoS.
Can't we use a less specific hash in the URL, one that omits the specific weights and CSS files, and instead only cares about the set of asset libraries and a particular group?
Weight is excluded from the hash explicitly - I added a method to do this. Weight is (still :(...) incremented programmatically when assets are added, so it's completely unreliable.
We want the files to vary by information like version and files though IMO, otherwise the 'race conditions' part of the issue title doesn't get fixed.
Then you can have graceful degradation, because the set of asset libraries rarely changes. Groups change more often, but if a group is empty after a deployment, then fine, you return an empty aggregate file. Once cached HTML responses disappear, requests for such an empty aggregate would disappear.
It does gracefully degrade - it'll serve a file from PHP if the libraries and groups match. What it won't do is write that file to disk if the hash doesn't match - which ensures you always get either a 100% correct aggregate or an uncached one. This is a lot more graceful degradation than the current aggregation, which relies 100% on files being left on the filesystem for a configurable period.
This results in private, no-store being sent always, thus preventing aggregates from being cached. Looks like an oversight.
No this is intentional. Once a file is written to disk, it will be sent with the headers of the file, not the ones set in PHP. That means things like Etag, expires etc. all come from the file - if we set them in PHP they'll be arbitrary, and you can have the situation of one CDN endpoint serving a PHP version and one CDN endpoint serving the file version with different headers.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
how do I know, only given library B as a query parameter, that jQuery has already been loaded?
The "already loaded libraries" query parameter (which comes from
ajaxPagestate) also is a minimally representative subset. Which means that all of the dependencies of that minimally representative subset have also been loaded. Therefore, jQuery has been loaded.
It's always up to the server side to expand that to the full list (by adding all (recursive) dependencies to this set) whenever necessary. That's what\Drupal\Core\Asset\LibraryDependencyResolverInterface::getLibrariesWithDependencies()is for. And that's exactly what\Drupal\Core\Asset\AssetResolver::getLibrariesToLoad()does: it takes the requested libraries, expands it to include deps, and it takes the already loaded libraries, expands that too, then diffs them.It’s not clear from your comment which of these you prefer
Sorry. I think we should not break BC for code, and hence keep the old classes functionally equivalent. But I think all sites should migrate to use the new behavior: no behavioral BC.
however it would only be used to provide a list, not useful for anything else
That'd be fine. :)
but then we're writing to state for no reason, or that patch could add it in - since it changes the information written to state slightly anyway?.
I don't quite understand this sentence.
Right now the methods on these classes are very long and do too many things IMO
Agreed! We just took the old ancient logic, split it up in very rough phases, and made those the interfaces. They're likely not granular enough.
There’s a route for css and a route for js, and two different controllers, the only parameter is the file name.
I see that, but I don't understand why it works like this, if we have to go through great pains for image styles to make it work.
If they were able to write to the disk, then I'd be concerned about DoS.
Ah! I misread the code. The unconditional
$match = TRUEthrew me off.It does gracefully degrade - it'll serve a file from PHP if the libraries and groups match.
I see that now. But I actually meant graceful degradation in the sense of it still writing those to disk, so that you don't have to regenerate the same aggregate asset over and over again. But I guess this is at least a step forward: in the past, it'd be a 404. Now it'll be a 200. Though one has to wonder what the potential server impact that could be, if somehow an old HTML response is being served by some proxy, and these aggregates have to be created a lot of times.
Once a file is written to disk, it will be sent with the headers of the file, not the ones set in PHP.
Riiight! That makes a lot of sense :) I'd like to see this become clearer then: it looks as if the second
$headers = […]is going to be different, but it's always identical to the first one. So there's no need to specify that separately. Also, it's probably not necessary to have it be a variable on the class then, it can just be hardcoded, because this behavior is always desirable. - 🇬🇧United Kingdom catch
The "already loaded libraries" query parameter (which comes from ajaxPagestate) also is a minimally representative subset. Which means that all of the dependencies of that minimally representative subset have also been loaded. Therefore, jQuery has been loaded.
It's always up to the server side to expand that to the full list (by adding all (recursive) dependencies to this set) whenever necessary. That's what \Drupal\Core\Asset\LibraryDependencyResolverInterface::getLibrariesWithDependencies() is for. And that's exactly what \Drupal\Core\Asset\AssetResolver::getLibrariesToLoad() does: it takes the requested libraries, expands it to include deps, and it takes the already loaded libraries, expands that too, then diffs them.Right, this is exactly what the patch implements - it takes the already loaded libraries query parameter, then passes it along to the asset controllers. I think you mistook my explanatory comment for a bug report - it's not, it's just explanatory. I'd failed to implement this in earlier versions of the patch, and we hadn't discussed it in the issue (because last time we discussed this seriously we'd barely got to minimally representative sets at all iirc), so it seemed worth a comment.
functionally equivalent. But I think all sites should migrate to use the new behavior: no behavioral BC.
OK that's the current status of the patch, so good!
I don't quite understand this sentence.
I mean if this patch adds that state entry, then we're writing to state and never getting anything out of it, which seems a bit wasteful. The current implementation in HEAD needs the state entry to work at all, and the interface method looked completely unnecessary to me - just added because the information was there.
It looks to me like JsLicenseWebLabelsAnnotator from #2258313: Add license information to aggregated assets → should maintain the list in state maybe?
I see that, but I don't understand why it works like this, if we have to go through great pains for image styles to make it work.
It's because image styles have {image_style}/{filename} to worry about, this is just {filename}. If there was a route for every image style, there'd probably be less hoops (but more routes).
I see that now. But I actually meant graceful degradation in the sense of it still writing those to disk, so that you don't have to regenerate the same aggregate asset over and over again.
If we wrote to disk for invalid hashes based on the uri, then it would be possible to fill a disk by requesting 000s of invalid hashes - which is proper DoS at that point. The patch is trying to balance graceful degradation vs. DoS.
If we really wanted to, we could write a single file (or cache entry) for the library + group (using your less-specific hash suggestion), then serve that from the controller instead of recalculating the aggregate - but then that's still a bit of trade off of disk/cache space vs. processing and we'd still hit PHP every time. One thing we could do is set cacheable headers for that case, then at least you don't hit PHP if you keep requesting the same file.
Also, it's probably not necessary to have it be a variable on the class then, it can just be hardcoded, because this behavior is always desirable.
Fabianx asked for it to be a property on the class so that the headers can be extended - specifically for Akamai which needs Edge-Control. I don't really want to add support for Akamai to core, but I can see making it easier for contrib to support custom headers.
- 🇬🇧United Kingdom catch
One thing we could do is set cacheable headers for that case, then at least you don't hit PHP if you keep requesting the same file.
We should probably not do this though - a few minutes after typing it I thought of the following:
1. Roll some code to production with an updated library definition, pages are cached in CDN, files are cached in CDN.
2. Roll back the code. Now the hashes on those cached pages are invalid. CDN gets a cache miss, Drupal generates the now invalid aggregate with the current code base, adds cacheable headers.
3. Deploy the code again. The CDN has the incorrect aggregate cached from step #2.
So even a hash that is currently invalid may become valid in the future, and always serving those from PHP with uncacheable headers seems safest. Or we could put a really short TTL on them with a long comment if we're concerned about abuse.
- 🇬🇧United Kingdom catch
OK two things that I didn't entirely answer previously that the updated patch doesn't do:
1. Still writing to state and implementing getAll() - I still think we should deprecate that and re-implement it for #2258313: Add license information to aggregated assets → in the class that actually needs it, but interested to see what you think.
2. #26/#28 this is needed because we don't always write to a file there, although I cleaned it up a bit.
Still needs tests but CNR for the bot etc.
The last submitted patch, 215: 1014086-215.patch, failed testing.
The last submitted patch, 215: 1014086-215.patch, failed testing.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
It looks to me like JsLicenseWebLabelsAnnotator from #2258313: Add license information to aggregated assets → should maintain the list in state maybe?
How could it? If you're suggesting it should decorate this service, then… how can that work in a generic way, i.e. what if somebody overrode the default asset aggregation handling with a custom strategy, then that won't work anymore. Hence that method on the interface.
- 🇬🇧United Kingdom catch
I meant in the optimize method - since we pass all aggregates to it:
+++ b/core/includes/theme.inc @@ -1342,6 +1342,12 @@ function template_preprocess_html(&$variables) { + \Drupal::service('asset.js.collection_optimizer_license_web_labels_annotator')->optimize($js_assets_header); + \Drupal::service('asset.js.collection_optimizer_license_web_labels_annotator')->optimize($js_assets_footer);But then means we'd be getting/setting the state entry on runtime again given it's called from template_preprocess_html(), so you're right it's not a good option.
- 🇬🇧United Kingdom catch
This restores the state entry when using the new services.
Adding some more test coverage next assuming this comes back green.
- 🇬🇧United Kingdom catch
Adding some test coverage. Also missed a bit when adding back the state service, and tidying up CssAssetController and JsAssetController.
There's a limit to how much we can assert with the tests - the non-php headers depend on server configuration, don't want to look at the content of the files since this will change.
The last submitted patch, 222: 1014086-222.patch, failed testing.
- 🇬🇧United Kingdom catch
Test passes fine for me locally both running via phpunit and run-tests.sh
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
I see there's URL-related stuff going on. I wonder whether this is because your local installation is not installed in a subdirectory. Testbot is installed in a subdirectory.
- 🇬🇧United Kingdom catch
Ran locally with a sub-directory, I did get a fail but not the same one.
Updating the patch since there's a better way to handle the url, but something still up with this.
The last submitted patch, 226: 1014086-225.patch, failed testing.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
You'll need to modify your test to
var_dump()the entire response body, so you can see the PHP error that is triggering this 500 response. - 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
The last patch is missing
AssetDumperUriInterfaceAFAICT :) - 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
This means DrupalCI is eating PHP fatals caused by missing classes. This is not good. Pinged the infra team.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
What catch didn't mention is that he tried
var_dump(),print_r(),$this->fail()et cetera, and none of it resulted in output he could see on DrupalCI. - 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
#220: as we just discussed, we totally can get rid of the reliance on
state, by usingfile_scan_directory(). But a complication for that would be that it's not the service that implementsgetAll()that is responsible for dumping to disk; so it'd be impossible for it to know where to usefile_scan_directory()(remote storage notwithstanding). - 🇬🇧United Kingdom catch
Yeah I think it's worth discussing that in a follow-up, the status quo of the patch is that it doesn't actually change the state entry (but it makes it write-only until web licenses need it). I'd been quite excited about completely getting rid of the need to store anything in the database for this, but can live with that bit not changing - everything else here is more important.
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
-
+++ b/core/lib/Drupal/Core/Asset/AssetCollectionGroupOptimizerInterface.php @@ -0,0 +1,21 @@ + public function optimizeGroup(array $group); +++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerTrait.php @@ -0,0 +1,78 @@ + public function optimizegroup(array $group) {Inconsistent capitalization. And interesting that PHP doesn't complain about this!
-
+++ b/core/lib/Drupal/Core/Asset/AssetGroupSetHashTrait.php @@ -0,0 +1,28 @@ + * Generate a hash for an asset group set. ... + * @param array $groups + * A set of asset groups. ... + protected function generateHash(array $groups) {"groups" imply ordered list of groups.
"group set" implies order doesn't matter.
Which is it?
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,147 @@ + * The grouper for js assets.s/js/JS/
or
s/js/JavaScript/ -
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,147 @@ + * The cache file name is retrieved on a page load via a lookup variable that"cache file name" sounds strange. Should this be "aggregate file name"?
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,147 @@ + * in $css while the value is the cache file name. The cache file is generatedWhat is
$css? Should this be$css_assets? -
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,147 @@ + $css_assets = array();Nit: s/array()/[]/
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,147 @@ + // Generate a URL each group of assets, but do not process them inline, this"Generate a URL each group of assets" -> something is missing there
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,147 @@ + // is done using self::optimizeGroup() when the asset path is requested.This
selfseems strange. -
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,147 @@ + $ajax_page_state = $this->requestStack->getCurrentRequest()->query->get('ajax_page_state');->queryshould be omitted. See\Drupal\Core\Render\HtmlResponseAttachmentsProcessor::processAttachments(). -
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,147 @@ + $query_parameters = [Supernit: s/parameters/args/
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,158 @@ + * File names are generated based on library/asset definitions. This includes + * a hash of the assets and the group index. Additionally the full set of + * libraries, already loaded libraries and theme are sent as query parameters + * to allow a PHP controller to generate a valid file with sufficient + * information. Files are not generated by this method since they're assumed + * to be successfully returned from the URL created whether on disk or not.Why is the comment ehre so very different?
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,158 @@ + /** + * {@inheritdoc} + */ + public function getAll() { + return []; + }Should be deleted; the trait implements this.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerTrait.php @@ -0,0 +1,78 @@ + // Append a ';' and a newline after each JS file to prevent them + // from running together.Nit: 80 cols.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + * The Asset Resolver.Nit: s/Asset Resolver/asset resolver/
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + * The Theme Initialization.Nit: s/Theme/theme/
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + // whole is validated against a hash of the CSS assets later on.This is the generic base class; it should not mention CSS or JS.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + $key = $this->generateHash($groups); ... + $hash = $file_parts[2]; ... + if ($key !== $hash) {We generate a hash and name it
$key. And we receive a hash and name it$hash.This is confusing. What about
$generated_hashand$received_hash? -
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,263 @@ + $match = TRUE; ... + $match = FALSE; + } + + if (!file_exists($uri)) { + $data = $this->optimizer->optimizeGroup($group); + // Dump the optimized CSS for this group into an aggregate file. + if ($match) {The way
$matchis calculated here and then used later on is very confusing.Let's start to make this more understandable by moving the logic to compare hashes to a separate helper method?
(I still think the code in this controller is very hard to undrestand.0
-
+++ b/core/modules/system/src/Routing/AssetRoutes.php @@ -0,0 +1,75 @@ + * Defines a routes callback to register a url for serving assets.Nit: two spaces between "callback" and "to".
Nit: s/url/URL/
-
+++ b/core/tests/Drupal/FunctionalTests/Asset/AssetOptimizationTest.php @@ -0,0 +1,76 @@ + public function testAssetAggregation() {I'm not seeing explicit test coverage of the three different scenarios described in the asset controller, and the consequences of each (i.e. file being generated on disk or not).
-
- 🇬🇧United Kingdom catch
1. Fixed.
2. I wanted a word to describe a unique collection of assets, that wasn't too loaded, and wasn't just 'array'. The order does matter in that we use both the group delta and hash in the filename to identify exactly which specific aggregate file to generate. AssetGroupSetHashTrait seemed more explicit for this than AssetGroupsHashTrait. Better naming suggestions welcome.
3. s/js/CSS :P
4. Replaced with the same docs as the js version, which was actually updated from the old docs.
5-17: yep, fixed.
18. This was extra complicated because it was looking to see if there was a file for an invalid URL. However if there was a file for an invalid URL, we'd not hit PHP because it'll just get the file instead. So I've completely removed the $match variable and shortened the function a bit. There's still some length, but most of it is boilerplate and comments now - any better?
19. Fixed
20. Added that test coverage.
- 🇫🇷France nod_ Lille
Just to appreciate what's in scope what's in follow-ups.
If we explicitly have the libs in the urls of assets, we could get rid of
drupalSettings.ajaxPageState.librariesand get it when needed (it'll be fast enough).How about having
&libraries=core/jquery,core/drupalinstead of&libraries[0]=core/jquery&libraries[1]=core/drupalsame as what we have indrupalSettings.ajaxPageState.librariesactually.In JsAssetController, line 30:
protected $assetType = 'css';shouldn't that be js?In JsCollectionOptimizerLazy:
$query_args = [ 'libraries' => $this->dependencyResolver->getMinimalRepresentativeSubset($libraries), 'theme' => $this->themeManager->getActiveTheme()->getName(), 'already_loaded' => $this->dependencyResolver->getMinimalRepresentativeSubset($already_loaded), ];What's the use of already_loaded? the ajax framework ought to take care of this no (and it's empty from what I see).
After applying the patch quickedit (at least) broke, looks like there are files missing from the aggregate (didn't look too much into it yet).
- 🇬🇧United Kingdom catch
If we explicitly have the libs in the urls of assets, we could get rid of drupalSettings.ajaxPageState.libraries and get it when needed (it'll be fast enough).
You mean parse it out of the URLs? That would then rely on this specific approach being used, which we can't guarantee, so not sure it's doable. Sounds like follow-up anyway though.
How about having &libraries=core/jquery,core/drupal instead of &libraries[0]=core/jquery&libraries[1]=core/drupal same as what we have in drupalSettings.ajaxPageState.libraries actually.
Hmm that'd save some bytes from the URLs, seems reasonable.
In JsAssetController, line 30: protected $assetType = 'css'; shouldn't that be js?
Definitely should!
What's the use of already_loaded? the ajax framework ought to take care of this no (and it's empty from what I see).
If we POST to an AJAX URL, we send the already loaded libraries in AJAX page state. That request then only renders libraries that aren't already loaded.
With this patch, when we POST to an AJAX URL, we send the already loaded libraries in AJAX page state. That request then generates a URL with the minimal representative set for the libraries that aren't already loaded. The minimal representative set, when expanded to include its dependencies, can include libraries that were already loaded. So specifically for URLs generated by AJAX requests, we have to send both the minimal representative set of already loaded libraries and the libraries to load, so that we can generate an aggregate containing only the intersection of the two. It took me a while to figure that out, which is why there's the long comment that Wim pointed out earlier. You're correct it's empty for non-AJAX requests, in that case it's a no-op.
The alternative would be to send every library we need to load, but that's going to be a longer URL in most cases.
After applying the patch quickedit (at least) broke, looks like there are files missing from the aggregate (didn't look too much into it yet).
I'll have a look next time.
- 🇫🇷France nod_ Lille
Oh i get it makes sense. For the naming I'd make sense to replace
libraries, already_loadedbyinclude, exclude. That's the terminology most, if not all, asset optimizers use in nodejs land. - 🇬🇧United Kingdom catch
@nod_ we use alreadyLoadedLibraries() in the aggregation system already, but include/exclude is fine, and also less bytes, so changed.
Patch fixes everything from #238. Quick edit broken was because I missed #235-9 in the js asset controller, which meant the exclude logic wasn't working and we got all the js again in one big aggregate.
Test coverage didn't catch that, I don't have ideas on how to make it catch it except inspecting either file contents or file size, which would be incredibly brittle test coverage.
- 🇬🇧United Kingdom catch
And the interdiff because d.o js for upload field isn't working for me this morning, in case you thought it was impossible to have any more redundant comments from me on this issue.
- 🇩🇪Germany Fabianx
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -125,13 +125,13 @@ public function optimize(array $js_assets) { - $ajax_page_state = $this->requestStack->getCurrentRequest()->query->get('ajax_page_state'); + $ajax_page_state = $this->requestStack->getCurrentRequest()->get('ajax_page_state');Is that an intentional change?
- 🇩🇪Germany Fabianx
Should that not then also be done for all the other query parameters like include/exclude?
- 🇬🇧United Kingdom catch
AJAX requests can be GET or POST, but we know the controller is only going to have GET requests with query parameters, so I don't think it should.
- 🇬🇧United Kingdom catch
DrupalCI didn't pick the patch up, trying again (no changes).
The last submitted patch, 248: 1014086-241.patch, failed testing.
- 🇬🇧United Kingdom catch
Only need to see exclude in the query string if it's got something in it, this is why the test failures.
Also updates the test to check for a 200 when we have an invalid library - nothing in the asset system actually validates that a library exists, so either we can't make a group and you get a 400, or we can and you get an uncached-200, or it's valid apart from the wrong library, and the file will be created correctly anyway - since we hash on the library definitions, not the list of libraries.
I opened #2808063: LibraryDiscoveryParser::buildByExtension() doesn't validate that extensions exist → for one aspect of that missing library validation.
The last submitted patch, 250: 1014086-250.patch, failed testing.
The last submitted patch, 242: 1014086-241.patch, failed testing.
- heddn Nicaragua
Is the issue summary accurate? It says this has only been implemented for CSS, not JS. But later comments in here seem to allude to js being covered now.
Drupal 8.3.0-alpha1 will be released the week of January 30, 2017, which means new developments and disruptive changes should now be targeted against the 8.4.x-dev branch. For more information see the Drupal 8 minor version schedule → and the Allowed changes during the Drupal 8 release cycle → .
- 🇬🇧United Kingdom catch
Trying to get this moving again, here's a re-roll to start since it no-longer applied.
- 🇬🇧United Kingdom catch
This needs updating for the deprecation policy, but apart from short array syntax just a straight re-roll otherwise.
- 🇬🇧United Kingdom catch
Self-reviewed, a few changes:
1. Dropped the *OptimizerTraits - they were removing code duplication from a deprecated class, which makes it rule of one-and-a-half instead of rule of three, better to just duplicate the code into the new classes.
2. Updated for the new deprecation guidelines, and added a change record
Couple more things:
- the hash trait should probably be @internal
- some other things should be @internal too - there's too much API surface here as evidenced by having to deprecate so much for what should have just been an implementation change.
The last submitted patch, 259: 1014086-259.patch, failed testing. View results →
Drupal 8.4.0-alpha1 will be released the week of July 31, 2017, which means new developments and disruptive changes should now be targeted against the 8.5.x-dev branch. For more information see the Drupal 8 minor version schedule → and the Allowed changes during the Drupal 8 release cycle → .
- 🇬🇧United Kingdom catch
Fixing the duplicate property declaration plus some code style stuff.
Drupal 8.5.0-alpha1 will be released the week of January 17, 2018, which means new developments and disruptive changes should now be targeted against the 8.6.x-dev branch. For more information see the Drupal 8 minor version schedule → and the Allowed changes during the Drupal 8 release cycle → .
- 🇧🇪Belgium borisson_ Mechelen, 🇧🇪
I don't understand a lot of what's happening in this patch, but since this seems to be a solid improvement I can at least offer a review.
Most of these are nits, but I hope it can help get the ball rolling on this issue again.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -4,8 +4,15 @@ +@trigger_error('The ' . __NAMESPACE__ . '\CssCollectionOptimizer is deprecated in Drupal 8.4.0 and will be removed before Drupal 9.0.0. Instead, use ' . __NAMESPACE__ . '\CssCollectionOptimizerLazy', E_USER_DEPRECATED);Should be updated to 8.5.0?
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -4,8 +4,15 @@ + * @deprecated as of Drupal 8.3.x, will be removed before Drupal 9.0.0 + * Instead you should use \Drupal\Core\Asset\CssCollectionOptimizerLazyWe should also change 8.3.x to 8.5.x here?
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -184,4 +196,14 @@ public function deleteAll() { + */ + public function getAll() {I might be wrong, but from the diff in dreditor this indentation looks off.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,206 @@ +use \Drupal\Core\Theme\ThemeManagerInterface; + +use \Symfony\Component\HttpFoundation\RequestStack; +/**The newline should be moved one line down here.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,206 @@ + * Optimizes CSS assets. + */Should this be:
Optimizes a collection of CSS assets.? -
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,206 @@ + * {@inheritdoc} + * + * File names are generated based on library/asset definitions. This includesI don't think it's allowed to mix interitdoc + actual documentation in the same docblock.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,206 @@ + // Group the assets.This is a useless comment. I'd rather see a comment here about why we need
$key. -
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,206 @@ + $query_args = [ + 'theme' => $this->themeManager->getActiveTheme()->getName(), + 'include' => implode(',', $this->dependencyResolver->getMinimalRepresentativeSubset($libraries)), + ];Indentation here looks off.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,206 @@ + // rules must precede any other style, so we move those to the + // top.80 cols, top can be on the previous line.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,206 @@ + */ + public function getAll() { + return $this->state->get('drupal_css_cache_files', []); + }Indentation.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizer.php @@ -4,9 +4,16 @@ +@trigger_error('The ' . __NAMESPACE__ . '\JsCollectionOptimizer is deprecated in Drupal 8.4.0 and will be removed before Drupal 9.0.0. Instead, use ' . __NAMESPACE__ . '\JsCollectionOptimizerLazy', E_USER_DEPRECATED); ... + * @deprecated as of Drupal 8.3.x, will be removed before Drupal 9.0.0Core versions.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizer.php @@ -187,4 +199,13 @@ public function deleteAll() { + } }There should be a newline following the method declaration.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,218 @@ +use \Drupal\Core\Theme\ThemeManagerInterface; + +use \Symfony\Component\HttpFoundation\RequestStack;This newline should be removed.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,218 @@ + protected $state; + + + /**Needs only one newline.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,218 @@ + if ($libraries) {Let's be explicit here,
if (!empty($libraries)), because that's actually what's intended with the code. -
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,261 @@ + $response = new Response($data, 200, ['Cache-control' => $this->cacheControl, 'Content-Type' => $this->contentType]);Does the cache control here need to be in a property? That doesn't seem like something someone would want to override without also overwriting this method.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,261 @@ + abstract protected function getGroups(AttachedAssetsInterface $attached_assets, Request $request); +}Needs newline.
-
+++ b/core/modules/system/src/Routing/AssetRoutes.php @@ -0,0 +1,75 @@ + // Generate assets. If clean URLs are disabled image derivatives will always + // be served through the routing system. If clean URLs are enabled and the + // image derivative already exists, PHP will be bypassed.This comment seems invalid, this talks about image derivatives and we don't seem to be handling those here.
-
+++ b/core/tests/Drupal/FunctionalTests/Asset/AssetOptimizationTest.php @@ -0,0 +1,140 @@ + protected function assertAggregate($url, $from_php = TRUE) { ... + protected function assertInvalidAggregates($url) { ... + protected function replaceGroupDelta($url) { ... + protected function replaceGroupHash($url) { ... + protected function setInvalidLibrary($url) { ... + protected function omitTheme($url) {All of these methods should get a docblock describing what they do.
-
+++ b/core/tests/Drupal/FunctionalTests/Asset/AssetOptimizationTest.php @@ -0,0 +1,140 @@ + +Should be only one newline.
-
- 🇦🇹Austria fago Vienna
I've seen a (minor) issue that should be resolvable with this: 🐛 [PP-1] Race condition with locale javascript translation generation Postponed
Drupal 8.7.0-alpha1 will be released the week of March 11, 2019, which means new developments and disruptive changes should now be targeted against the 8.8.x-dev branch. For more information see the Drupal 8 minor version schedule → and the Allowed changes during the Drupal 8 release cycle → .
Drupal 8.6.0-alpha1 will be released the week of July 16, 2018, which means new developments and disruptive changes should now be targeted against the 8.7.x-dev branch. For more information see the Drupal 8 minor version schedule → and the Allowed changes during the Drupal 8 release cycle → .
@fago yes tho that patch simply returns if the file doesnt exist... if there's a really bad condition and the file should exist but does not... then it's sad times trying to debug :(
- 🇺🇸United States mariacha1
I'm re-rolling this patch for 8.8, which takes care feedback items 1, 2, and 11 above, but none of the others. Happy to clean up some of the other nitpicks once I can apply this and see if it still works as hoped.
- 🇺🇸United States mariacha1
Ok, working through the code, I see #269 doesn't apply the filesystem changes to the new lazy classes, so here's the patch with that applied as well. This patch also does the following things:
- Group the use statements and removes initial backslash
- Removes a docblock for `deleteAll()` that duplicates its parent verbatim
- Rearranges the getAll and deleteAll functions so they're easier to compare to the deprecated classes.
- 🇺🇸United States mariacha1
Current problem seems to be that my recieved hash never matches my generated hash, so the files are never created.
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,261 @@ + if ($received_hash == $generated_hash) { The last submitted patch, 272: 1014086-272.patch, failed testing. View results →
- codesniffer_fixes.patch Interdiff of automated coding standards fixes only.- 🇬🇧United Kingdom martin107
A) file_scan_directory is deprecated. and is triggering errors.
https://www.drupal.org/node/3038437 →
B) New cases of array() converted to []. as per coding standard
- 🇺🇸United States Mixologic Portland, OR
I do not know what is wrong with the patch in #274, but it is filling the disk on a testbot with errors, and then the zombie bot lives on and fails a bunch of builds.
Can you please run some of those tests locally first? Something is fundamentally broken with that patch.
https://dispatcher.drupalci.org/job/drupal_patches/10430/consoleFull is an example of a job that filled the disk.
- 🇬🇧United Kingdom martin107
Sorry for causing a mess.
I do not know what is wrong with the patch
After playing with this some more .. it because every
in 271 mariacha1 pointed out
Current problem seems to be that my recieved hash never matches my generated hash, so the files are never created.
in short for every test, the css and the js is 404'ing and so an avalanche of errors... my mistake
I am just posting one of our new url
/sites/default/files/css/css_0_eea631ea3cbc9e1a1c33518177e18dda52ac5f633ac13e55b48606de60fed335.css?theme=bartik&include=core/normalize%2Csystem/base%2Ccontextual/drupal.contextual-links%2Cquickedit/quickedit%2Cviews/views.module%2Ctoolbar/toolbar%2Ctour/tour-styling%2Ccontextual/drupal.contextual-toolbar%2Cuser/drupal.user.icons%2Cshortcut/drupal.shortcut%2Cbartik/global-styling%2Cclassy/base%2Cclassy/messages
While I think about the fix.
I am posting some minor changes here ... and deliberately not triggering the testbot.
A) I have fixup approx 35 coding standard errors.
B) For both CssCollectionOptimizerLazy.php and JsCollectionOptimizerLazy.php I am directory injecting the config_factory and dropping calls to \Drupal::config()
Drupal 9.2.0-alpha1 → will be released the week of May 3, 2021, which means new developments and disruptive changes should now be targeted for the 9.3.x-dev branch. For more information see the Drupal core minor version schedule → and the Allowed changes during the Drupal core release cycle → .
Drupal 9.1.0-alpha1 → will be released the week of October 19, 2020, which means new developments and disruptive changes should now be targeted for the 9.2.x-dev branch. For more information see the Drupal 9 minor version schedule → and the Allowed changes during the Drupal 9 release cycle → .
Drupal 8.9.0-beta1 → was released on March 20, 2020. 8.9.x is the final, long-term support (LTS) minor release of Drupal 8, which means new developments and disruptive changes should now be targeted against the 9.1.x-dev branch. For more information see the Drupal 8 and 9 minor version schedule → and the Allowed changes during the Drupal 8 and 9 release cycles → .
Drupal 8.8.0-alpha1 will be released the week of October 14th, 2019, which means new developments and disruptive changes should now be targeted against the 8.9.x-dev branch. (Any changes to 8.9.x will also be committed to 9.0.x in preparation for Drupal 9’s release, but some changes like significant feature additions will be deferred to 9.1.x.). For more information see the Drupal 8 and 9 minor version schedule → and the Allowed changes during the Drupal 8 and 9 release cycles → .
- 🇬🇧United Kingdom martin107
I did not fix the errors ...yet.
a) Fixed up some errors I introduced from 276
b) Added, fixed up a few @throws tags.
- 🇳🇿New Zealand quietone
Just the reroll.
Next will be fixing the coding standards. - 🇳🇿New Zealand quietone
Fix coding standards and remove use of deprecated functions.
- 🇳🇿New Zealand quietone
Tracked the test failures to the call to scanDirectory, which throws an exception. To get the tests running again I restored the check on whether the directory exists or not. This is in both CssCollectionOptimizerLazy and JsCollectionOptimizerLazy.
if (is_dir('public://css')) { $this->fileSystem->scanDirectory('public://css', '/.*/', ['callback' => $delete_stale]); }There are also coding standard fixes and removal of the use of deprecated code in the patch.
- 🇫🇷France nod_ Lille
-
+++ b/core/lib/Drupal/Core/Asset/AssetResolver.php @@ -148,6 +148,7 @@ public function getCssAssets(AttachedAssetsInterface $assets, $optimize) { + $options['_library'] = $library;This is nice, will allow some more interesting things I think.
-
+++ b/core/modules/system/src/Controller/JsAssetController.php @@ -0,0 +1,67 @@ + // so filter them out. Settings are always in the header.This is not true anymore, settings are in the footer by default now. The rest of the comment is accurate
-
- 🇬🇧United Kingdom catch
I've fixed the comment in #287.2. Also further updated the issue summary to add more details, so removing that tag.
- 🇬🇧United Kingdom catch
I'm adding 'needs manual testing' for this one too (and tagging Novice for that). We have some automated test coverage, but apart from enabling aggregation for loads of functional JS tests, I'm not sure it will really flush out subtle bugs here, since it's about what exactly we send to browsers.
To test:
1. Install - probably with Bartik, Olivero or Unami since it'll be obvious if something is visually broken.
2. Ensure asset aggregation is enabled in admin/config/development/performance
3. Make sure CSS continues to render OK in both the front-end and admin theme.
4. Try clicking around something that uses javascript like the views UI, contextual links, taxonomy term drag and drop.
5. Check your browser network tab to make sure you're getting 200s for CSS/JS aggregates, and check they're actually written to disk.
- 🇫🇷France nod_ Lille
Quick test on my end, haven't spent a lot of time with it and didn't try advagg or similar modules:
- Olivero/seven, aggregation enabled.
- CSS/JS renders OK on frontend and admin
- Views ui works, olivero js works
- Aggregates gets loaded and written to disk
It's looking good, I'm really glad we're starting to get the library info down to the aggregate functions and even the frontend, at this point it's realistic to build
drupalSettings.ajaxPageState.librariesdynamically now that we have the information in the aggregates URLs, we could also add the library information to the individual script tags (when aggregation is off). But that's definitely a followup. - 🇬🇧United Kingdom catch
Contrib modules that might be affected:
https://www.drupal.org/project/flysystem → - extends CssCollectonOptimizer http://grep.xnddx.ru/node/31835087
advagg actually doesn't extend/replace CssCollectionOptimizer as far as I can see, but it may well be relying on behaviour from the core services that this patch might break. More generally there will be issues fixed by this patch that advagg has taken a different approach to, that it will probably need to adapt for.
WinCacheDrupal extends JsCollectionOptimizer: http://grep.xnddx.ru/node/31033622
Both classes are deprecated, and no-longer used by the core services, so the extensions of them won't break, but the fact that the core service definitions have changed might disrupt things. I think opening an issue against those modules once this one is RTBC would be enough here.
Drupal 9.3.0-rc1 → was released on November 26, 2021, which means new developments and disruptive changes should now be targeted for the 9.4.x-dev branch. For more information see the Drupal core minor version schedule → and the Allowed changes during the Drupal core release cycle → .
- 🇬🇧United Kingdom catch
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -174,21 +169,40 @@ protected function generateHash(array $css_group) { - return $this->state->get('drupal_css_cache_files'); + public function optimizeGroup(array $group) { + // Optimize each asset within the group. + $data = ''; + foreach ($group['items'] as $asset) { + $data .= $this->optimizer->optimize($asset);One question: with both this and the JS version, we're adding the ::optimizeGroup() method to satisfy AssetCollectionGroupOptimizerInterface, but not actually implementing the method, should we:
1. Update the class so it implements the new interface (might make things easier for subclasses maybe)?
2. Just deprecate the class and not bother to change it at all?
- 🇫🇷France nod_ Lille
Tried to update to 9.4 but I think i missed something somewhere. An issue in the CSS part.
- 🇺🇸United States mradcliffe USA
I am removing the Novice tag from this issue because the issue isn't ready to be tested at the moment. I think once there's a working patch, then it can be added back.
I’m using this documentation as a source: https://www.drupal.org/community/contributor-guide/task/triage-novice-is... →
The last submitted patch, 298: 1014086-298.patch, failed testing. View results →
- 🇬🇧United Kingdom catch
Need to account for the new unit test added in #2936067: CSS aggregation fails on many variations of @import → .
I marked the old one legacy, and created a new unit test, testing the same thing - some of the mocking is a bit different due to the different implementation.
Interdiff shows the difference between the tests after a copy and git add.
- 🇬🇧United Kingdom catch
Back to green, added the Novice tag back for manual testing.
- 🇺🇸United States dww
This mostly looks great, thanks! A bunch of nits and a few things of substance. Didn't make it through the tests yet, but wanted to save what I've got so far. Happy to fix most of these, but a couple require some feedback from someone who understands what's happening here better than I do. 😉 I'm not sure any of this is actually worthy of NW, could mostly / entirely be done in a follow-up.
-
+++ b/core/lib/Drupal/Core/Asset/AssetCollectionGroupOptimizerInterface.php @@ -0,0 +1,21 @@ + * Optimizes a specific group assets.group of assets.
-
+++ b/core/lib/Drupal/Core/Asset/AssetCollectionGroupOptimizerInterface.php @@ -0,0 +1,21 @@ + * @param array $group + * An asset group.Is the structure of this
$grouparray documented anywhere? Can we add a @see or something? -
+++ b/core/lib/Drupal/Core/Asset/AssetCollectionGroupOptimizerInterface.php @@ -0,0 +1,21 @@ + * @return array + * The optimized string for the group.🤔 an array that's called the "optimized string"? Is this an array of strings? Can we document that (both via
string[]notarrayand in words)? -
+++ b/core/lib/Drupal/Core/Asset/AssetCollectionGroupOptimizerInterface.php @@ -0,0 +1,21 @@ + public function optimizeGroup(array $group);Add the return type
: array? -
+++ b/core/lib/Drupal/Core/Asset/AssetDumperUriInterface.php @@ -0,0 +1,25 @@ + * The uri to dump to."URI" (caps) in comments (as a few lines below).
-
+++ b/core/lib/Drupal/Core/Asset/AssetDumperUriInterface.php @@ -0,0 +1,25 @@ + public function dumpToUri($data, $file_extension, $uri);: stringreturn type? -
+++ b/core/lib/Drupal/Core/Asset/AssetGroupSetHashTrait.php @@ -0,0 +1,29 @@ + protected function generateHash(array $groups) {Return type?
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -178,21 +169,44 @@ protected function generateHash(array $css_group) { + * Optimizes a specific group assets.group of assets.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -178,21 +169,44 @@ protected function generateHash(array $css_group) { + public function optimizeGroup(array $group) {Return type?
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -178,21 +169,44 @@ protected function generateHash(array $css_group) { + // http://www.w3.org/TR/REC-CSS2/cascade.html#at-import, @import + // rules must precede any other style, so we move those to the + // top. The regular expression is expressed in NOWDOC since it is + // detecting backslashes as well as single and double quotes. It + // is difficult to read when represented as a quoted string.this could be wrapped differently now that it's not as indented.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -178,21 +169,44 @@ protected function generateHash(array $css_group) { - * {@inheritdoc} + * Deletes all optimized asset collections assets.This is still documented in
AssetCollectionOptimizerInterface, why change this? -
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -201,4 +215,14 @@ public function deleteAll() { + public function getAll() {Return type?
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,237 @@ +class CssCollectionOptimizerLazy implements AssetCollectionGroupOptimizerInterface {:bikeshed: would
CssCollectionLazyOptimizerbe easier to read and make sense of? 😉 -
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,237 @@ + if (!$file_system) { + @trigger_error('The file_system service must be passed to CssCollectionOptimizer::__construct(), it is required before Drupal 9.0.0. See https://www.drupal.org/node/3006851.', E_USER_DEPRECATED); + $file_system = \Drupal::service('file_system'); + }That's no longer the name of this constructor, nor does that seem like the right version to be referencing here. I haven't been following this area of the code at all, but this seems off.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,237 @@ + * {@inheritdoc} + * + * File names are generated based on library/asset definitions. This includesI thought we weren't allowed to extend {@inheritdoc} comments. Although I definitely appreciate these docs, so if we can't keep them here, let's move them into the parent docs or inline inside the function below...
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,237 @@ + public function optimize(array $css_assets) {Return type? For everything else in this class?
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizer.php @@ -184,13 +176,14 @@ public function getAll() { - * {@inheritdoc} + * Deletes all optimized asset collections assets.And here... why change {@inheritdoc}?
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,243 @@ +class JsCollectionOptimizerLazy implements AssetCollectionGroupOptimizerInterface {JsCollectionLazyOptimizer? -
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,243 @@ + if (!$file_system) { + @trigger_error('The file_system service must be passed to JsCollectionOptimizer::__construct(), it is required before Drupal 9.0.0. See https://www.drupal.org/node/3006851.', E_USER_DEPRECATED); + $file_system = \Drupal::service('file_system'); + }Same concerns as above with the name of the function and the version.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,272 @@ +abstract class AssetControllerBase extends FileDownloadController { ... + * Constructs a CssAssetController object.Not sure how to best document the constructor for an abstract base class, but this probably isn't it. 😉 Probably should reference
AssetControllerBasehere. -
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,272 @@ + // Headers sent from PHP can never perfectly match those sent when the + // file is served by the filesystem, so ensure this request does not get + // cached in either the browser or reverse proxies. Subsequent requests + // for the file will be served from disk and be cached. This is done to + // avoid situations such as where one CDN endpoint is serving a version + // cached from PHP, while another is serving a version cached from disk. + // Should there be any discrepancy in behaviour between those files, this + // can make debugging very difficult.The care that went in to both this code and the comment are fabulous. 💗 Thanks so much!
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,272 @@ + * Get grouped assets. ... + abstract protected function getGroups(AttachedAssetsInterface $attached_assets, Request $request);Missing
@returndocs and return type. -
+++ b/core/modules/system/src/Controller/CssAssetController.php @@ -0,0 +1,55 @@ + /** + * The content type. + * + * @var string + */ + protected $contentType = 'text/css'; + + /** + * The asset type. + * + * @var string + */ + protected $assetType = 'css'; +++ b/core/modules/system/src/Controller/JsAssetController.php @@ -0,0 +1,67 @@ + /** + * The content type. + * + * @var string + */ + protected $contentType = 'application/javascript'; + + /** + * The asset type. + * + * @var string + */ + protected $assetType = 'js';Can't all these be {@inheritdoc} since they're explained in the base class?
-
+++ b/core/modules/system/system.routing.yml @@ -520,3 +520,6 @@ system.csrftoken: + +route_callbacks: + - '\Drupal\system\Routing\AssetRoutes::routes'Got up to here in the review. Saving the comment before I get to the tests since I'm not sure I trust dreditor as much anymore. ;)
-
- 🇺🇸United States dww
Only trivial nits for the tests. All this could be follow-up material.
-
+++ b/core/tests/Drupal/FunctionalTests/Asset/AssetOptimizationTest.php @@ -0,0 +1,191 @@ + public function testAssetAggregation() {Should we add
: voidto all the new functions in this class? -
+++ b/core/tests/Drupal/FunctionalTests/Asset/AssetOptimizationTest.php @@ -0,0 +1,191 @@ + /** + * @param string $url ... + /** + * @param string $url ... + /** + * @param string $url ... + /** + * @param string $urlMissing 1-liner summary.
-
+++ b/core/tests/Drupal/Tests/Core/Asset/CssCollectionOptimizerLazyUnitTest.php @@ -31,8 +34,10 @@ class CssCollectionOptimizerUnitTest extends UnitTestCase { + * Test that css imports with strange letters do not destroy the css output. +++ b/core/tests/Drupal/Tests/Core/Asset/CssCollectionOptimizerUnitTest.php @@ -31,8 +31,12 @@ class CssCollectionOptimizerUnitTest extends UnitTestCase { + * Test that css imports with strange letters do not destroy the css output.It's existing, but since we're doing some cleanup (e.g. purging
setUp()):- 'Tests'.
- We try to do 'CSS' in comments.
-
- 🇺🇸United States dww
This fixes most of #303 and all of #304.
#303
- ✔️
- TODO
- Yeah, this should be
@return string. Fixed. - Yes, but
: string. 👍 - ✔️
- ✔️
- ✔️
- 👍
- ✔️
- ✔️
- ✔️
- ❌ No, that's an existing method. We can't change the signature here.
- TBD. 😉 I can see the wisdom of having "CollectionOptimizer" next to each other, so probably ignore this.
- TBD. Help.
- TODO
- Done for places where we're implementing new methods that have them. Left methods from existing interfaces alone.
- ✔️
- TBD, probably not.
- TODO
- Took a stab.
- 💗
- Added.
- ✔️
- 👍
#304
- Mostly, yes. Except the ones that should be
: string. 😉 - Added, and @return docs.
- ✔️
Interdiff seems slightly confused about the file copies or not, so I'm also attaching a raw diff of the two .patch files. /shrug
But there, now I don't feel so bad about the long-winded dreditor nit review...
Thanks! -Derek
- 🇺🇸United States dww
Sorry about that. Now with
sh ./core/scripts/dev/commit-code-check.sh --branch 9.4.xpassing locally. 😅 Thanks phpcbf. 😉 - 🇬🇧United Kingdom catch
I've opened 📌 Dynamically determine ajaxPageState based on libraries Active for #1014086-238: Stampedes and cold cache performance issues with css/js aggregation → and documented a couple of other issues that are blocked/helped by this one to the issue summary.
- 🇫🇷France nod_ Lille
I can write initial preliminary docs but docs finishing and touch ups are my cryptonite so I'll leave it to someone else. Manual testing that I can do :)
Manual testing:
Aggregation off => no change as expected.
Aggregation on:- Installation screen, OK (there is no aggregation there)
- After installing umami I'm getting an error:
Symfony\Component\HttpKernel\Exception\BadRequestHttpException: Invalid filename. in Drupal\system\Controller\AssetControllerBase->getGroup() (line 256 of core/modules/system/src/Controller/AssetControllerBase.php).for the request
http://drupal.local/sites/default/files/css/css_6_653afb28cdbbcb8b5f771169ebf0dbede4b1e3edaf5b64a4589018dd90de1a44.css?include=core/normalize%2Csystem/base%2Ctour/tour-styling%2Ccontextual/drupal.contextual-links%2Cviews/views.module%2Ctoolbar/toolbar%2Ccontextual/drupal.contextual-toolbar%2Cuser/drupal.user.icons%2Cshortcut/drupal.shortcut%2Cumami/global%2Cumami/classy.base%2Cumami/messages%2Cumami/classy.node%2Cumami/more-link%2Cumami/demo-umami-tour%2Cumami/recipe-collections%2Cumami/view-mode-card-common%2Cumami/view-mode-card-common-alt&theme=umami - I don't see any generated file saved in
files/jsorfiles/cssfolders, they're empty. - Using views UI doesn't seem to cause issues
- CKEditor 5 UI and admin UI is working fine
- Media library does it's job in CKEditor 5
- Not seeing style/scripts breaks while going around the front and admin UI
Remarks:
- One potential issue now that the generation of the aggregate and the response are separated is that we might run into #1988968: Drupal.ajax does not guarantee that "add new JS file to page" commands have finished before calling said JS → more than previously. If you have a filter that minify JS and takes a bit of time we might make is very easy to trigger without #1988968: Drupal.ajax does not guarantee that "add new JS file to page" commands have finished before calling said JS → .
- Another thing that we might want to consider is to avoid running extra filters during the aggregation for requests that are not going to be cached, to ensure we don't spend time unnecessarily. Then again you might need to run a filter all the time even if it's not saved for some reason, so an opt-in thing would be good probably.
- When the aggregation fails we're sending a fully rendered HTML page, is that ok? seems like dynamic page cache serves it but that 404 also links to a css aggregate that triggers an error…
- 🇫🇷France nod_ Lille
seems like olivero generates the files properly, the hash matches. But claro/umami doesn't work as expected.
- 🇬🇧United Kingdom catch
I tried to reproduce nod_'s issues in #1014086-308: Stampedes and cold cache performance issues with css/js aggregation → and tried a load of things without successfully reproducing, then finally I did.
What I think are the shortest steps to reproduce:
1. Install Umami
2. Switch off aggregation from admin/config/development/performance
3. Switch aggregation back on againAfter this, I started to get the same 'invalid filename' error clicking around Umami.
Then I looked at where it was getting thrown, and it was in
AssetControllerBase::getGroup()The URL that failed was:
sites/default/files/css/css_6_969d818bd370fb89df10f751bb527f78005b1ec1236de8043da0b9cc4f40185c.css?include=core/normalize%2Csystem/base%2Ccontextual/drupal.contextual-links%2Cviews/views.module%2Ctoolbar/toolbar%2Ctour/tour-styling%2Ccontextual/drupal.contextual-toolbar%2Cuser/drupal.user.icons%2Cshortcut/drupal.shortcut%2Cumami/global%2Cumami/classy.base%2Cumami/messages%2Cumami/classy.node%2Cumami/more-link%2Cseven/tour-styling%2Cumami/recipe-collections%2Cumami/view-mode-card&theme=umamiThe group delta is the first part of the URL - 6.
If I var_dump array_keys($groups), there I get:
array(4) { [0]=> int(0) [1]=> int(1) [2]=> int(2) [3]=> int(3) }So 6 is indeed not in there.
I then look at the page HTML, and there's this:
<link rel="stylesheet" media="all" href="/sites/default/files/css/css_0_81641114faa8417524cf1c197cbf28a1935a2370214e9a79893861bb098ee535.css?theme=umami&include=core/normalize%2Csystem/base%2Ctour/tour-styling%2Ccontextual/drupal.contextual-links%2Cviews/views.module%2Ctoolbar/toolbar%2Ccontextual/drupal.contextual-toolbar%2Cuser/drupal.user.icons%2Cshortcut/drupal.shortcut%2Cumami/global%2Cumami/classy.base%2Cumami/messages%2Cumami/classy.node%2Cumami/more-link%2Cumami/demo-umami-tour%2Cumami/recipe-collections%2Cumami/view-mode-card-common%2Cumami/view-mode-card-common-alt"> <link rel="stylesheet" media="screen" href="/sites/default/files/css/css_1_81641114faa8417524cf1c197cbf28a1935a2370214e9a79893861bb098ee535.css?theme=umami&include=core/normalize%2Csystem/base%2Ctour/tour-styling%2Ccontextual/drupal.contextual-links%2Cviews/views.module%2Ctoolbar/toolbar%2Ccontextual/drupal.contextual-toolbar%2Cuser/drupal.user.icons%2Cshortcut/drupal.shortcut%2Cumami/global%2Cumami/classy.base%2Cumami/messages%2Cumami/classy.node%2Cumami/more-link%2Cumami/demo-umami-tour%2Cumami/recipe-collections%2Cumami/view-mode-card-common%2Cumami/view-mode-card-common-alt"> <link rel="stylesheet" media="all" href="/sites/default/files/css/css_2_81641114faa8417524cf1c197cbf28a1935a2370214e9a79893861bb098ee535.css?theme=umami&include=core/normalize%2Csystem/base%2Ctour/tour-styling%2Ccontextual/drupal.contextual-links%2Cviews/views.module%2Ctoolbar/toolbar%2Ccontextual/drupal.contextual-toolbar%2Cuser/drupal.user.icons%2Cshortcut/drupal.shortcut%2Cumami/global%2Cumami/classy.base%2Cumami/messages%2Cumami/classy.node%2Cumami/more-link%2Cumami/demo-umami-tour%2Cumami/recipe-collections%2Cumami/view-mode-card-common%2Cumami/view-mode-card-common-alt"> <link rel="stylesheet" media="all" href="/sites/default/files/css/css_3_81641114faa8417524cf1c197cbf28a1935a2370214e9a79893861bb098ee535.css?theme=umami&include=core/normalize%2Csystem/base%2Ctour/tour-styling%2Ccontextual/drupal.contextual-links%2Cviews/views.module%2Ctoolbar/toolbar%2Ccontextual/drupal.contextual-toolbar%2Cuser/drupal.user.icons%2Cshortcut/drupal.shortcut%2Cumami/global%2Cumami/classy.base%2Cumami/messages%2Cumami/classy.node%2Cumami/more-link%2Cumami/demo-umami-tour%2Cumami/recipe-collections%2Cumami/view-mode-card-common%2Cumami/view-mode-card-common-alt"> <link rel="stylesheet" media="all" href="https://fonts.googleapis.com/css?family=Open+Sans:400,400i,700,700i"> <link rel="stylesheet" media="all" href="https://fonts.googleapis.com/css?family=Scope+One"> <link rel="stylesheet" media="all" href="/sites/default/files/css/css_6_81641114faa8417524cf1c197cbf28a1935a2370214e9a79893861bb098ee535.css?theme=umami&include=core/normalize%2Csystem/base%2Ctour/tour-styling%2Ccontextual/drupal.contextual-links%2Cviews/views.module%2Ctoolbar/toolbar%2Ccontextual/drupal.contextual-toolbar%2Cuser/drupal.user.icons%2Cshortcut/drupal.shortcut%2Cumami/global%2Cumami/classy.base%2Cumami/messages%2Cumami/classy.node%2Cumami/more-link%2Cumami/demo-umami-tour%2Cumami/recipe-collections%2Cumami/view-mode-card-common%2Cumami/view-mode-card-common-alt">So we have the four aggregates that show up in groups, two standalone file assets for google fonts, and then aggregate 6 which is unrecognised.
Then... I compared aggregate 6 to aggregate 3, and:
These are the same libraries, with the same hash, with the same theme, the only thing different is the group delta, which is as it should be. So the main request is producing the extra group(s), but the aggregate request is not.
I switched away from the patch, and the number of groups in the HTML and their locations were the same (obviously URLs are different).
Then I looked at umami.libraries.yml and noticed the two google fonts libraries have no weight. When I added a weight of 100 for each, I got four aggregates, then the two standalone files, and no errors any more (this change):
diff --git a/core/profiles/demo_umami/themes/umami/umami.libraries.yml b/core/profiles/demo_umami/themes/umami/umami.libraries.yml index 310b14f139..abb6dc2e3c 100644 --- a/core/profiles/demo_umami/themes/umami/umami.libraries.yml +++ b/core/profiles/demo_umami/themes/umami/umami.libraries.yml @@ -92,7 +92,7 @@ webfonts-open-sans: gpl-compatible: false css: theme: - 'https://fonts.googleapis.com/css?family=Open+Sans:400,400i,700,700i': { type: external, minified: true } + 'https://fonts.googleapis.com/css?family=Open+Sans:400,400i,700,700i': { type: external, minified: true, weight: 100 } webfonts-scope-one: remote: https://fonts.google.com @@ -102,7 +102,7 @@ webfonts-scope-one: gpl-compatible: false css: theme: - 'https://fonts.googleapis.com/css?family=Scope+One': { type: external, minified: true } + 'https://fonts.googleapis.com/css?family=Scope+One': { type: external, minified: true, weight: 100 } view-mode-card: css:So the issue is happening when there are aggregate groups, interrupted by a non-aggregated asset, then another aggregate group after that.
Then I looked closer at the aggregate URL, and noticed the google fonts libraries weren't in the URL.
So I checked CssCollectionOptimizerLazy, and noticed when we have unpreprocessed or external libraries, we're not adding the library to the array to pass to the aggregate controllers. And..... that's the problem. For the first four aggregates, it was finding them fine because they'd be the same if the other libraries were never on the page, and I think the last aggregate included the files from the invalid one, because it couldn't know it was supposed to be split into two, which is why everything looks the same because all the CSS is there. The google fonts libraries aren't aggregates, so that's OK too, but then you get to the final aggregate, and it's missing the context necessary to know it got split out from everything else, so you get an invalid aggregate, that would also in practice be empty if we tried to create it instead of throwing an error.
Patch includes the fix.
We should add some test coverage for this because it's tricky. I think it looks something like this:
Add a unit test of CssCollectionOptimizerLazy::optimize()
We need to inject the file_url_generator service which is currently got via \Drupal::service().
Pass in an array of $css_assets with multiple files and multiple libraries attached:
1. Aggregated in library 1.
2. Unaggregated/external in library 2
3. Aggregated in library 3
With the files weighted in that order, so that the unaggregated files split the aggregate into two groups.
Then the test could parse a generated URL that it gets back from this method, extract the library names, and make sure they match what we put in.
When the aggregation fails we're sending a fully rendered HTML page, is that ok?
In this case we're getting the error due to an essentially malformed URL, so I think it's OK - only this bug or a semi-malicious request is likely to hit it. The only other option would be some kind of early print with the error but we don't really do that elsewhere.
- 🇳🇱Netherlands spokje
Updated patch in #310 🐛 Stampedes and cold cache performance issues with css/js aggregation Fixed with some minor readability changes and injecting of Time- and FileUrlGenerator services.
Note for interdiff: The changes in
core/core.services.ymllook weird, I _think_ the changes in the original patch(es) where against a version from many moons ago. The only changes I've made are adding the Time- and FileUrlGenerator services to bothasset.css.collection_optimizerandasset.js.collection_optimizer. - 🇫🇷France nod_ Lille
That solved my issue with the CSS file, on the JS side though, still nothing saved in public://js/ with umami.
There is no information about the language with that request actually, that is a problem for ckeditor5 which does some fancy library manipulation to load the cke5 translation files. With this patch, CKE5 is not localized. It means we're missing a test with aggregation on for CKE5 UI translation
I think the hook_js_alter() and hook_css_alter() are going to be problematic here. not sure how to deal with that since we don't want to serialize the whole context in the filename either…
- 🇬🇧United Kingdom catch
There is no information about the language with that request actually, that is a problem for ckeditor5 which does some fancy library manipulation to load the cke5 translation files.
We need that for both locale and ckeditor5, easy to add to the URL and then set on the request in the controller, but as you say can't do that for every aspect of the request. However I think we can document the limitations in hook_js/css_alter()?
- 🇫🇷France nod_ Lille
For the first issue about the context should we have the page cachetags in the url or something? that way whatever is used to make a variation should work? It might be too big and expose even more internal drupal stuff though.
On the saving aggregate to disk it might make sense to test using the hash of the library definition instead of the content of the aggregate. It would allow to write files even when there is a _js/css_alter() hook running for some reason. As long as we have the page context so that the various alter hooks can do their work.
Very much on board about adding some restrictions and docs to make this more predictible.
- 🇫🇷France nod_ Lille
Or should/could we have 2 ways of doing this? like having unalterable libraries that can work with this new thing, and keep the current behavior around for the js/css alter needs? it might feel like adding a second problem on top of the first one instead of simplifying though…
- 🇬🇧United Kingdom catch
For the first issue about the context should we have the page cachetags in the url or something? that way whatever is used to make a variation should work? It might be too big and expose even more internal drupal stuff though.
This won't work for a couple of reasons:
1. We'd have to send these as query arguments, so if the file is already written and they change, you're out of luck.
2. There's a possibility of running into URL length issues (possibly not as bad now IE is going out of support, but we did a lot of work in prerequisites to this issue to cut down bytes in the URL).However I think we are fine if we only add language to the URL - this is already a restriction on hook_js_alter() due to the way assets are cached https://api.drupal.org/api/drupal/core%21lib%21Drupal%21Core%21Asset%21A...
Remembered this when looking through contrib uses of hook_js_alter() which refer back to these docs.There are a lot, I went through about 60 or so but not the full list.
Most hook_js_alter() implementations are either static logic, checking config or the database, or in one case using environment variables - all of these would be fine.
Only 8.x+ modules I could find that are doing anything with the current request (other than language) are these two:
https://www.drupal.org/project/css_js_performance_improvement → - this is using hook_js_alter() to re-implement the entire asset aggregation system, it should be customising the aggregation system instead, and it has zero users. The current logic in there won't work due to the caching logic for asset resolving we already have.https://www.drupal.org/project/restrict_ip → - this tries to remove all js assets from the page (except two) if an IP address doesn't match. I think this will already fall foul of the current caching logic (but also seems unnecessary to do what it's doing, seems like very legacy code ported from 7.x a long time ago and left since then). However since it operates by IP address I don't think the current patch will make things better or worse.
On the saving aggregate to disk it might make sense to test using the hash of the library definition instead of the content of the aggregate.
We're sort of doing this already I think. Current core logic (and very old versions of the patch) is to hash the actual file contents, and we're avoiding that so that we don't have to process the aggregates in the main page request and track aggregate hashes in the db.
The current logic in the patch is to hash the 'groups' - i.e. the array of asset information from libraries once it's been passed through
AssetCollectionGrouperInterface::group(), this guarantees a consistent file at the same URL, or no file being written and assets still being served via PHP.keep the current behavior around for the js/css alter needs?
Locale module does a catch all of translating potentially any JavaScript file it sees, so I don't think that's an option.
Will see what's going on with CSS aggregate files not getting written, then look at adding the language to the URL next.
- 🇬🇧United Kingdom catch
I tracked down the issue with the JavaScript aggregates not being written.
The problem is that with JavaScript, we process groups twice with different sets of assets - once for the header and once for the footer. The logic to do this in the patch is mostly fine, however Umami exposed yet another edge case bug.
Because we process groups twice, JsCollectionOptimizeLazy was building a list of $libraries (to add as a query argument on the URL) based on either the header or footer assets passed in, but not the full list.
With Umami, this resulted in exactly the same assets being included in the aggregate request, which should work fine. But... because it was building this list without the full context of all the libraries for the request, something in the library dependency logic was resulting in the resulting list of assets being in a different order.. 📌 Replace custom weights with dependencies in library declarations; introduce "before" and "after" for conditional ordering Needs work , plus maybe some logic to normalize the lists of assets as much as possible, would make all this a bit more robust.
However with the current state, the order of assets could be meaningful in other circumstances, so again it's a sign of the hash comparison logic working correctly, but we obviously need for it to pass unless there's an invalid/stale request.
The answer to this is to pass the $libraries for the request (as a whole) to AssetCollectionOptimizerInterface::optimize(). This probably isn't allowable under the bc policy so we may need to overload the method calls and add the parameter to the implementations, and then add a commented out parameter to be changed in a major release. Or something like that.
However with that change, it not only fixes the bug but also simplifies the logic in the implementations a fair bit. I went through a couple of dead-ends before getting to this, that were not so simple.
There's a more general issue that the various interfaces/classes in the asset aggregation system are to large extent a result of converting procedural code to classes, and don't really represent a coherent API for making all of this pluggable. We might want to look into deprecating the collection optimizer interface altogether and merging things into the AssetResolver class, which would be a bigger thing to override but allow a bit more control for implementations to do what they want. I'm not suggesting trying to do that in this 300+ comment issue though.
I still need to fix the locale/language issue, and this is something we can add to the js version of the unit tests for ::optimize() (that $libraries passed in also ends up on the resulting URL), but a better place to continue from. Also the language issue is hopefully straightforward.
- 🇬🇧United Kingdom catch
Discussing the bug in #320 with berdir, nod and dww in slack made me think of a further optimisation.
Currently, the filename is $group_$hash, with language to be added. $hash is the hash of all the assets needed on a request.
Instead of this we can put $group into a query parameter, and make hash the hash of the (unoptimized) assets for the specific group.
The controller then uses the libraries + language + theme + group delta (+ scope for js) to build up the assets for the group. It can then compare the hash of the group to the hash in the filename.
This would mean that if two identical assets in the same order are in group 2 on one page, and group 3 on another, they'd resolve to the same filename on disk, and either request would be able to generate identical file contents and verify it. This should improve cache hit rates over the current approach.
berdir also pointed me to 🐛 Library order asset weights do not work properly when a large number of javascript files is loaded between two jQuery UI libraries Fixed in case that was the cause of the js ordering bug. I don't think it's the root cause because it's possible to get identical assets sets if you start from identical library sets, but it's certainly related and improvements there could improve cache hit rates too.
- 🇫🇷France nod_ Lille
Use the group content, and most query arguments to build the file hash. Still need to switch the language.
The JS has an ordering issue from what is generated in the page request and the rebuilt group information in the separate request (a polyfill is above/below the jquery file) so that doesn't match for me.
- 🇫🇷France nod_ Lille
Tried to look into it but I do no know how to dynamically change the language for the request based on a query parameter. We can't use path negociation since the URL points directly to a file. the session-language code for the negociator doesn't help me figuring out how to do it either.
- 🇬🇧United Kingdom catch
+++ b/core/lib/Drupal/Core/Asset/AssetGroupSetHashTrait.php @@ -10,19 +10,26 @@ trait AssetGroupSetHashTrait { + $normalized += array_intersect_key($query, $query_context);We shouldn't need to include theme, group, delta, or scope as part of the hash, since they should already be accounted for by the content of $assets. Just language is fine here I think. Or actually language would affect the content of $assets too (or not matter if it doesn't) so maybe even that is optional in the hash?
Drupal 9.4.0-alpha1 → was released on May 6, 2022, which means new developments and disruptive changes should now be targeted for the 9.5.x-dev branch. For more information see the Drupal core minor version schedule → and the Allowed changes during the Drupal core release cycle → .
The last submitted patch, 324: core-agg-1014086-324.patch, failed testing. View results →
- 🇫🇷France nod_ Lille
removed the query stuff, seems to be working better like this.
Still need the language handling to be fixed here.
The last submitted patch, 329: core-agg-1014086-329.patch, failed testing. View results →
- 🇬🇧United Kingdom catch
Re-roll for 10.1.x and fixing the fatal error in CssCollectionOptimizerLazyUnitTest.
- 🇳🇱Netherlands spokje
Love the interdiff, "might" need the actual patch as well... 😇
- 🇫🇷France andypost
-
+++ b/core/core.services.yml @@ -1616,8 +1616,8 @@ services: + arguments: [ '@asset.css.collection_grouper', '@asset.css.optimizer', '@theme.manager', '@library.dependency_resolver', '@request_stack', '@state', '@file_system', '@config.factory', '@file_url_generator', '@datetime.time', '@language_manager'] @@ -1630,8 +1630,8 @@ services: + arguments: [ '@asset.js.collection_grouper', '@asset.js.optimizer', '@theme.manager', '@library.dependency_resolver', '@request_stack', '@state', '@file_system', '@config.factory', '@file_url_generator', '@datetime.time', '@language_manager'] +++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,273 @@ + public function optimize(array $css_assets, array $libraries) { ... + public function getAll() { ... + public function deleteAll() { ... + public function optimizeGroup(array $group): string {it smells ...I bet it needs split service
OTOH it has just few methods...
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -2,11 +2,19 @@ +@trigger_error('The ' . __NAMESPACE__ . '\CssCollectionOptimizer is deprecated in drupal:9.4.0 and is removed from drupal:10.0.0. Instead, use ' . __NAMESPACE__ . '\CssCollectionOptimizerLazy. See https://www.drupal.org/node/2888767', E_USER_DEPRECATED); ... + * @deprecated in drupal:9.4.0 and is removed from drupal:10.0.0. Instead, use + * \Drupal\Core\Asset\CssCollectionOptimizerLazy. +++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizer.php @@ -2,11 +2,19 @@ +@trigger_error('The ' . __NAMESPACE__ . '\JsCollectionOptimizer is deprecated in drupal:9.4.0 and is removed from drupal:10.0.0. Instead, use ' . __NAMESPACE__ . '\JsCollectionOptimizerLazy. See https://www.drupal.org/node/2888767', E_USER_DEPRECATED); ... + * @deprecated in drupal:9.4.0 and is removed from drupal:10.0.0. Instead use + * use \Drupal\Core\Asset\JsCollectionOptimizerLazy.as a bug it could fit into 9.5 but not 9.4
-
The last submitted patch, 335: core-agg-1014086-334.patch, failed testing. View results →
- 🇬🇧United Kingdom catch
Crosspost with nod_.
I took a look at adding $language as an argument to hook_js_alter(). Patch is against 10.1.x which is probably why my last patch didn't apply.
- 🇫🇷France nod_ Lille
Shouldn't we add language to the css_alter hook too?
Missing a service in the bigpipe module, and fixed some CKE5 code that was expecting a string instead of an object. CKE translations looks like they'd work without the JS issue below.
I do have an issue where
core/tabbableis not loaded as it should on the node edit page (of an umami article in spanish) and crashes the JS :/ haven't found out why yet. - 🇬🇧United Kingdom catch
Shouldn't we add language to the css_alter hook too?
I thought I had :/ apparently got distracted half way through.
- 🇬🇧United Kingdom catch
In retrospect it would've been better to work on some of this in a throwaway issue.
- 🇬🇧United Kingdom catch
OK back down to the Umami test failure now. The test passes for me locally and I can't reproduce the error that nod_ had either yet.
- 🇬🇧United Kingdom catch
Found the Umami issue - we had a line left over from older iterations of the patch overwriting the $libraries variable when an external file gets used, just need to remove the cruft.
- 🇫🇷France nod_ Lille
you know what, I think that did it :)
Reinstalled Umami, enabled CKE 5, don't have the issue with
core/tabbableanymore. Now to get that RTBC… - 🇬🇧United Kingdom catch
Cleaned up a few more things - some additional library tracking cruft. Made the $language parameter on getCssAssets() and getJsAssets() optional, implemented constructor bc.
- 🇫🇷France nod_ Lille
CKE 5 translations, views UI still work as expected.
Added a start of Release notes. The CR probably needs some more work too.
- 🇫🇷France nod_ Lille
Tried advanced aggregation → module with this patch on 9.5. The UI doesn't break at least but things are not working as intended.
Because the module alters some stuff in the JS/CSS asset definition, the file hash and generated hash do not match and the aggregates are not always written to disk. I didn't find that the generated aggregates from the module were used on the page either. Since there are a bunch of submodules for advagg I'm probably not testing the right things.
- 🇬🇧United Kingdom catch
I started making some updates to the CR - should be more or less up-to-date with the current status but could be fleshed out.
advagg will definitely need to update for some of the implicit behaviour changes here, if not the explicit API changes. Ideally the more we improve the core asset API the smaller it will get though.
- 🇧🇪Belgium borisson_ Mechelen, 🇧🇪
I found a couple nitpicks, only looked at the code, haven't done any manual testing yet.
-
+++ b/core/lib/Drupal/Core/Asset/AssetCollectionGroupOptimizerInterface.php @@ -0,0 +1,21 @@ +/** + * Interface defining a service that optimizes a collection of assets. + */Is this docblock correct? Looks like it is the same as the parent.
-
+++ b/core/lib/Drupal/Core/Asset/AssetDumperUriInterface.php @@ -0,0 +1,25 @@ + /** + * Dumps an (optimized) asset to persistent storage. + * + * @param string $data + * An (optimized) asset's contents.Do we need to repeat
(optimized)here? -
+++ b/core/lib/Drupal/Core/Asset/AssetDumperUriInterface.php @@ -0,0 +1,25 @@ + * @return string + * An URI to access the dumped asset.If we repeat the
optimizedabove here, should we add it here as well? -
+++ b/core/lib/Drupal/Core/Asset/AssetGroupSetHashTrait.php @@ -0,0 +1,32 @@ + $group_keys = array_flip(['type', 'group', 'media', 'browsers']);Can we just define the flipped array instead of doing this?
This shouldn't be a big performance difference but it does remove a function call; but I think it would be more clear.
-
+++ b/core/lib/Drupal/Core/Asset/AssetGroupSetHashTrait.php @@ -0,0 +1,32 @@ + // Remove some keys to make the hash more stable. + $omit_keys = array_flip(['weight']);Same here.
-
+++ b/core/lib/Drupal/Core/Asset/AssetResolver.php @@ -109,12 +110,15 @@ protected function getLibrariesToLoad(AttachedAssetsInterface $assets) { + public function getCssAssets(AttachedAssetsInterface $assets, $optimize, LanguageInterface $language = NULL) { + if (!isset($language)) { + $language = $this->languageManager->getCurrentLanguage(); + }Do we want to have the Language be something required in 11.x? We can also trigger a deprecation here in that case?
-
+++ b/core/lib/Drupal/Core/Asset/AssetResolver.php @@ -194,13 +198,16 @@ protected function getJsSettingsAssets(AttachedAssetsInterface $assets) { + public function getJsAssets(AttachedAssetsInterface $assets, $optimize, $language = NULL) { + if (!isset($language)) { + $language = $this->languageManager->getCurrentLanguage(); + }Same as above + can be typehinted as well.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -2,11 +2,19 @@ +@trigger_error('The ' . __NAMESPACE__ . '\CssCollectionOptimizer is deprecated in drupal:10.1.0 and is removed from drupal:11.0.0. Instead, use ' . __NAMESPACE__ . '\CssCollectionOptimizerLazy. See https://www.drupal.org/node/2888767', E_USER_DEPRECATED); ... + * @deprecated in drupal:9.4.0 and is removed from drupal:10.0.0. Instead, useShould be the same versions.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -58,13 +73,23 @@ class CssCollectionOptimizer implements AssetCollectionOptimizerInterface { + $this->time = $time;Do we need to provide a BC shim here?
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,271 @@ + /** + * {@inheritdoc} + * + * File names are generated based on library/asset definitions. This includes + * a hash of the assets and the group index. Additionally, the full set of + * libraries, already loaded libraries and theme are sent as query parameters + * to allow a PHP controller to generate a valid file with sufficient + * information. Files are not generated by this method since they're assumed + * to be successfully returned from the URL created whether on disk or not. + */Until this issue is in, it's not allowed to mix inheritdoc + another description.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,271 @@ + switch ($css_group['type']) { + case 'file': ... + case 'external':This switch only has 2 statements, do we need it to be a switch in that case? Is 2
ifstatements not clearer? -
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizer.php @@ -2,11 +2,19 @@ +@trigger_error('The ' . __NAMESPACE__ . '\JsCollectionOptimizer is deprecated in drupal:10.0.0 and is removed from drupal:11.0.0. Instead, use ' . __NAMESPACE__ . '\JsCollectionOptimizerLazy. See https://www.drupal.org/node/2888767', E_USER_DEPRECATED); ... + * @deprecated in drupal:9.4.0 and is removed from drupal:10.0.0. Instead useversion numbers + indentation of @deprecated
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,279 @@ + public function optimize(array $js_assets, array $libraries) {documentation same as previous comment.
-
- 🇬🇧United Kingdom catch
Thanks for the review!
#1: added an extra line of comment. I need to open a follow-up to look at re-organizing these interfaces more comprehensively (I think we need less of them).
#2 and #3: No I think it's redundant, removed.
#4 and #5: I kind of like array_flip() since it saves manually specifying meaningless array values when you only want the keys, but went ahead and spelt it out (with NULL array values).
#6: Couldn't really decide on this one - there are places where it's fine for it to be optional, so left it optional for now.
#7: added the type hint
#8: fixed
#9: added
#10: moved to an inline comment.
#11: I think this is copypasta from the old version, but might as well turn it into an if statement here.
#12 and #13: fixed
- 🇧🇪Belgium borisson_ Mechelen, 🇧🇪
After the last review I haven't found anything else to change on this patch, this is a really welcome cold cache performance improvement and the change record looks clear as well.
Also removed the needs manual testing tag, as that testing happened by @nod_.
- 🇬🇧United Kingdom catch
Opened #3299996: Rationalize asset aggregation interfaces → to look at options to generally make the API less cross-dependent and tied to implementation.
- 🇬🇧United Kingdom catch
Note to self that if this get committed, #1014086-321: Stampedes and cold cache performance issues with css/js aggregation → is a possible extra performance optimization that would be worth doing in a follow-up (no API implications as such so fine to do separately), or if we end up doing more work here might try to add it in.
- 🇬🇧United Kingdom catch
Removing race conditions from the issue title since that hasn't been true since the move from variable_get()/set() to the state system, shows how old this issue is.
- 🇬🇧United Kingdom alexpott 🇪🇺🌍
- The code to create assets on demand like image styles looks really neat and a much better approach than the current one.
- I've not thought about the answer to this question so it might be a silly question but: do we need something like an itok for asset generation?
-
+++ b/core/lib/Drupal/Core/Asset/AssetGroupSetHashTrait.php @@ -0,0 +1,40 @@ + return hash('sha256', serialize($normalized));I think that given this is going to be used as a filename that's eventually part of a request we should be using \Drupal\Component\Utility\Crypt::hashBase64() as that is "a base-64 encoded, URL-safe sha-256 hash."
Unless there is a good reason to not and if that's the case it should be documented.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -58,13 +73,27 @@ class CssCollectionOptimizer implements AssetCollectionOptimizerInterface { + // No deprecation because the entire class is deprecated. + if (!isset($time)) { + $time = \Drupal::time(); + }Given we are deprecating this I'm not sure that injecting the time service is worth it? Do we do this for testing? It doesn't look like it because I can't see any new legacy tests so I'm not sure the changes to this class are tested.
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -180,8 +193,24 @@ protected function generateHash(array $css_group) { /** * {@inheritdoc} */ - public function getAll() { - return $this->state->get('drupal_css_cache_files'); + public function optimizeGroup(array $group): string {The inheritdoc here is not correct. This class does not use the new interface so there are no docs to inherit. Do we have to change this class at all?
-
+++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizerLazy.php @@ -0,0 +1,269 @@ + /** + * Constructs a CssCollectionOptimizerLazy. + * + * @param \Drupal\Core\Asset\AssetCollectionGrouperInterface $grouper + * The grouper for CSS assets. + * @param \Drupal\Core\Asset\AssetOptimizerInterface $optimizer + * The asset optimizer. + * @param \Drupal\Core\Theme\ThemeManagerInterface $theme_manager + * The theme manager. + * @param \Drupal\Core\Asset\LibraryDependencyResolverInterface $dependency_resolver + * The library dependency resolver. + * @param \Symfony\Component\HttpFoundation\RequestStack $request_stack + * The request stack. + * @param \Drupal\Core\State\StateInterface $state + * The state key/value store. + * @param \Drupal\Core\File\FileSystemInterface $file_system + * The file system service. + * @param \Drupal\Core\Config\ConfigFactoryInterface $config_factory + * The config factory. + * @param \Drupal\Core\File\FileUrlGeneratorInterface $file_url_generator + * The file URL generator. + * @param \Drupal\Component\Datetime\TimeInterface $time + * The time service. + * @param \Drupal\Core\Language\LanguageManagerInterface $language_manager + * The language manager. + */ + public function __construct( + AssetCollectionGrouperInterface $grouper, + AssetOptimizerInterface $optimizer, + ThemeManagerInterface $theme_manager, + LibraryDependencyResolverInterface $dependency_resolver, + RequestStack $request_stack, + StateInterface $state, + FileSystemInterface $file_system, + ConfigFactoryInterface $config_factory, + FileUrlGeneratorInterface $file_url_generator, + TimeInterface $time, + LanguageManagerInterface $language_manager + ) { + $this->grouper = $grouper; + $this->optimizer = $optimizer; + $this->themeManager = $theme_manager; + $this->dependencyResolver = $dependency_resolver; + $this->requestStack = $request_stack; + $this->state = $state; + $this->fileSystem = $file_system; + $this->configFactory = $config_factory; + $this->fileUrlGenerator = $file_url_generator; + $this->time = $time; + $this->languageManager = $language_manager; + }Given this is a completely new class only in 10.1 - I think we should use constructor property promotion and read only properties - all the PHP 8.1 goodness. Especially typed properties.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizer.php @@ -58,13 +73,23 @@ class JsCollectionOptimizer implements AssetCollectionOptimizerInterface { + $this->time = $time;Here we're not doing the NULL check as we do for the CSS equivalent - but also I'm not sure we should be bothering with this as we're deprecating the whole class. Do we do this for testing? It doesn't look like it because I can't see any new legacy tests so I'm not sure the changes to this class are tested.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizer.php @@ -199,4 +210,25 @@ public function deleteAll() { + /** + * {@inheritdoc} + */ + public function optimizeGroup(array $group): string {This is not inheriting any docs.
-
+++ b/core/lib/Drupal/Core/Asset/JsCollectionOptimizerLazy.php @@ -0,0 +1,280 @@ + /** + * Constructs a JsCollectionOptimizerLazy. + * + * @param \Drupal\Core\Asset\AssetCollectionGrouperInterface $grouper + * The grouper for JS assets. + * @param \Drupal\Core\Asset\AssetOptimizerInterface $optimizer + * The asset optimizer. + * @param \Drupal\Core\Theme\ThemeManagerInterface $theme_manager + * The theme manager. + * @param \Drupal\Core\Asset\LibraryDependencyResolverInterface $dependency_resolver + * The library dependency resolver. + * @param \Symfony\Component\HttpFoundation\RequestStack $request_stack + * The request stack. + * @param \Drupal\Core\State\StateInterface $state + * The state key/value store. + * @param \Drupal\Core\File\FileSystemInterface $file_system + * The file system service. + * @param \Drupal\Core\Config\ConfigFactoryInterface $config_factory + * The config factory. + * @param \Drupal\Core\File\FileUrlGeneratorInterface $file_url_generator + * The file URL generator. + * @param \Drupal\Component\Datetime\TimeInterface $time + * The time service. + * @param \Drupal\Core\Language\LanguageManagerInterface $language_manager + * The language manager. + */ + public function __construct( + AssetCollectionGrouperInterface $grouper, + AssetOptimizerInterface $optimizer, + ThemeManagerInterface $theme_manager, + LibraryDependencyResolverInterface $dependency_resolver, + RequestStack $request_stack, + StateInterface $state, + FileSystemInterface $file_system, + ConfigFactoryInterface $config_factory, + FileUrlGeneratorInterface $file_url_generator, + TimeInterface $time, + LanguageManagerInterface $language_manager + ) { + $this->grouper = $grouper; + $this->optimizer = $optimizer; + $this->themeManager = $theme_manager; + $this->dependencyResolver = $dependency_resolver; + $this->requestStack = $request_stack; + $this->state = $state; + $this->fileSystem = $file_system; + $this->configFactory = $config_factory; + $this->fileUrlGenerator = $file_url_generator; + $this->time = $time; + $this->languageManager = $language_manager; + }As above I think we should use constructor promotion, readonly and typed properties here.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,312 @@ + /** + * The cache control header to use. + * + * @var string + */ + protected $cacheControl = 'private, no-store';This could do with a pointer to the excellent documentation that starts with "Headers sent form PHP can never perfectly match".
This confused me because I was like I'm sure we want to allow the aggregates to be cached.
Also could be a protected const rather than a property.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,312 @@ + /** + * Constructs an object derived from AssetControllerBase. + * + * @param \Drupal\Core\StreamWrapper\StreamWrapperManagerInterface $streamWrapperManager + * The stream wrapper manager. + * @param \Drupal\Core\Asset\LibraryDependencyResolverInterface $library_dependency_resolver + * The library dependency resolver. + * @param \Drupal\Core\Asset\AssetResolverInterface $asset_resolver + * The asset resolver. + * @param \Drupal\Core\Theme\ThemeInitializationInterface $theme_initialization + * The theme initializer. + * @param \Drupal\Core\Theme\ThemeManagerInterface $theme_manager + * The theme manager. + * @param \Drupal\Core\Asset\AssetCollectionGrouperInterface $grouper + * The asset grouper. + * @param \Drupal\Core\Asset\AssetCollectionOptimizerInterface $optimizer + * The asset collection optimizer. + * @param \Drupal\Core\Asset\AssetDumperUriInterface $dumper + * The asset dumper. + * @param \Drupal\Core\State\StateInterface $state + * The state service. + * @param \Drupal\Core\Language\LanguageManagerInterface $language_manager + * The language manager. + */ + public function __construct( + StreamWrapperManagerInterface $streamWrapperManager, + LibraryDependencyResolverInterface $library_dependency_resolver, + AssetResolverInterface $asset_resolver, + ThemeInitializationInterface $theme_initialization, + ThemeManagerInterface $theme_manager, + AssetCollectionGrouperInterface $grouper, + AssetCollectionOptimizerInterface $optimizer, + AssetDumperUriInterface $dumper, + StateInterface $state, + LanguageManagerInterface $language_manager + ) { + parent::__construct($streamWrapperManager); + $this->libraryDependencyResolver = $library_dependency_resolver; + $this->assetResolver = $asset_resolver; + $this->themeInitialization = $theme_initialization; + $this->themeManager = $theme_manager; + $this->grouper = $grouper; + $this->optimizer = $optimizer; + $this->state = $state; + $this->dumper = $dumper; + $this->languageManager = $language_manager; + $this->fileExtension = $this->assetType; + }Constructor promotion, typed properties and readonly.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,312 @@ + // First validate that the request is valid enough to produce an asset group + // aggregate. The theme must be passed as a query parameter, since assets + // always depend on the current theme. + if (!$request->query->has('theme')) { + throw new BadRequestHttpException('The theme must be passed as a query argument'); + } + if (!$request->query->has('delta') || !is_numeric($request->query->get('delta'))) { + throw new BadRequestHttpException('The numeric delta must be passed as a query argument'); + } + if (!$request->query->has('language')) { + throw new BadRequestHttpException('The language must be passed as a query argument'); + } ... + if (!isset($file_parts[1])) { + throw new BadRequestHttpException('Invalid filename'); + } ... + throw new BadRequestHttpException('Invalid filename.'); +++ b/core/modules/system/src/Controller/JsAssetController.php @@ -0,0 +1,66 @@ + if (!isset($scope)) { + throw new BadRequestHttpException('The URL must have a scope query argument.'); + }Are these failure modes tested?
-
+++ b/core/modules/system/src/Controller/CssAssetController.php @@ -0,0 +1,55 @@ + /** + * {@inheritdoc} + */ + protected $contentType = 'text/css'; + + /** + * {@inheritdoc} + */ + protected $assetType = 'css'; +++ b/core/modules/system/src/Controller/JsAssetController.php @@ -0,0 +1,66 @@ + /** + * {@inheritdoc} + */ + protected $contentType = 'application/javascript'; + + /** + * {@inheritdoc} + */ + protected $assetType = 'js';Should have property types.
-
+++ b/core/modules/system/src/Routing/AssetRoutes.php @@ -0,0 +1,75 @@ + /** + * The stream wrapper manager service. + * + * @var \Drupal\Core\StreamWrapper\StreamWrapperManagerInterface + */ + protected $streamWrapperManager; + + /** + * Constructs an asset routes object. + * + * @param \Drupal\Core\StreamWrapper\StreamWrapperManagerInterface $stream_wrapper_manager + * The stream wrapper manager service. + */ + public function __construct(StreamWrapperManagerInterface $stream_wrapper_manager) { + $this->streamWrapperManager = $stream_wrapper_manager; + }Constructor promotion, readonly and property types. The argument should also be camel case now.
- In general when we add new methods and properties in PHP 8.1 everything should be typehinted so we don't need to do an API change later to add this.
- 🇬🇧United Kingdom catch
#1 yay! It took a long time to get to the current solution both in this issue itself and the prerequisites over the years.
#2:
do we need something like an itok for asset generation?
The filenames of the files are a hash of the resolved assets (i.e. given a list of library names, the full array of assets from those library definitions and their dependencies). This hash is dependent therefore on both the combination of libraries and the code-base of the site.
If the file exists on disk then obviously it gets served. If it doesn't, then the controller can't figure out anything from the hash, what it does is take information from the URL arguments (language, theme, list of libraries), then run the same asset resolving and hashing logic.
If it comes up with the same hash, then we've got a valid request, and the asset is generated and written to disk.
If it comes up with a different hash but the libraries are valid, then we could have a race condition (cached HTML in a CDN from prior to a site update), or something nefarious. In this case, rather than the ITOK approach, we allow the controller to serve the aggregate as a response from PHP, but nothing at all is written to disk. So there is no disk-filling denial of service, and asset requests are no more expensive than normal uncached page requests generally (or a lot less).
If the libraries aren't valid or the theme is missing or similar, you get a 400.
So we only ever write to disk for a valid request. It would be theoretically possible if you had a site with the same code base, to copy complete asset URLs from your own site to another site, but you'd only be making valid aggregates. Also because the hashes are created from resolved assets, not just the list of libraries, just providing libraries in a different order or similar doesn't result in a different asset, we're using the 'minimum representative set' in the arguments then resolving this to the full assets including dependencies, so the hash would only differ if the resulting assets were actually different.
Two thoughts after writing this out:
- for extra hardening, it might be fine to use the site hash salt for the hash too. Then valid but transplanted URLs wouldn't result in a file on disk. Don't think it's an actual concern but it wouldn't hur.- I wonder if we could adopt the 'serve but don't write' logic for image derivatives with missing ITOK too. Not sure that ever came up at the time it was added in 7.20.
#3: yeah we should just use ::hashBase64(), no reason not to.
#4: I think this might be unnecessary.
#5: ditto
#6: 📌 Use PHP 8 constructor property promotion for existing code Needs work is currently postponed with no activity, I don't really want this to get bogged down in coding standards discussions especially given the coding standards group is moribund and it might end up requiring changes there. :/. If we can guarantee it won't, then fine - property promotion is nice.
#7: looks unnecessary.
#8: another unnecessary hunk hopefully.
#9: see #6.
#10: sounds good.
#11: see #9 and #6.
#12: see AssetOptimizationTest::testAssetAggregation() specifically ::assertInvalidAggregates() - basically it takes the valid aggregate URLs from the page, then makes invalid versions of them and makes sure we get a 400.
#13 yep.
#14: see #11, #9 and #6.
- 🇬🇧United Kingdom catch
Should address #368. Ran some tests locally but not everything.
- 🇬🇧United Kingdom catch
Sad interdiff:
diff --git a/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php index 5a913ea41d..8841866ff0 100644 --- a/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php +++ b/core/lib/Drupal/Core/Asset/CssCollectionOptimizer.php @@ -13,7 +13,7 @@ * @deprecated in drupal:10.1.0 and is removed from drupal:11.0.0. Instead, use * \Drupal\Core\Asset\CssCollectionOptimizerLazy. * - * @see https://www.drupal.org/node/2888767* + * @see https://www.drupal.org/node/2888767 */ class CssCollectionOptimizer implements AssetCollectionOptimizerInterface { - 🇧🇪Belgium borisson_ Mechelen, 🇧🇪
There is a change in the phpstan baseline file which looks like it is unrelated?
- 🇬🇧United Kingdom catch
It wasn't unrelated before due to unnecessary changes to those classes, but it's unrelated now because I just reverted those, good spot.
The last submitted patch, 373: 1014086-373.patch, failed testing. View results →
- 🇬🇧United Kingdom alexpott 🇪🇺🌍
-
+++ b/core/lib/Drupal/Core/Ajax/AjaxResponseAttachmentsProcessor.php @@ -70,6 +71,13 @@ class AjaxResponseAttachmentsProcessor implements AttachmentsResponseProcessorIn + protected $languageManager; @@ -87,8 +95,10 @@ class AjaxResponseAttachmentsProcessor implements AttachmentsResponseProcessorIn - public function __construct(AssetResolverInterface $asset_resolver, ConfigFactoryInterface $config_factory, AssetCollectionRendererInterface $css_collection_renderer, AssetCollectionRendererInterface $js_collection_renderer, RequestStack $request_stack, RendererInterface $renderer, ModuleHandlerInterface $module_handler) { + public function __construct(AssetResolverInterface $asset_resolver, ConfigFactoryInterface $config_factory, AssetCollectionRendererInterface $css_collection_renderer, AssetCollectionRendererInterface $js_collection_renderer, RequestStack $request_stack, RendererInterface $renderer, ModuleHandlerInterface $module_handler, LanguageManagerInterface $language_manager = NULL) { @@ -96,6 +106,11 @@ public function __construct(AssetResolverInterface $asset_resolver, ConfigFactor + if (!isset($language_manager)) { + @trigger_error('Calling ' . __METHOD__ . '() without the $language_manager argument is deprecated in drupal:10.1.0 and will be required in drupal:11.0.0', E_USER_DEPRECATED); + $language_manager = \Drupal::languageManager(); + } + $this->languageManager = $language_manager;I think we can add the property type here. Yes it is a bit inconsistent with other properties but it makes one less place to change stuff in the future.
Actually we can use property promotion here too. And then the deprecation becomes...
if (!isset($languageManager)) { @trigger_error('Calling ' . __METHOD__ . '() without the $languageManager argument is deprecated in drupal:10.1.0 and will be required in drupal:11.0.0', E_USER_DEPRECATED); $this->languageManager = \Drupal::languageManager(); } -
+++ b/core/lib/Drupal/Core/Asset/AssetDumperUriInterface.php @@ -0,0 +1,25 @@ + public function dumpToUri($data, $file_extension, $uri): string;We should have typehints on the params
-
+++ b/core/lib/Drupal/Core/Render/HtmlResponseAttachmentsProcessor.php @@ -80,6 +81,13 @@ class HtmlResponseAttachmentsProcessor implements AttachmentsResponseProcessorIn + /** + * The language manager. + * + * @var \Drupal\Core\Language\LanguageManagerInterface + */ + protected $languageManager; @@ -97,8 +105,10 @@ class HtmlResponseAttachmentsProcessor implements AttachmentsResponseProcessorIn - public function __construct(AssetResolverInterface $asset_resolver, ConfigFactoryInterface $config_factory, AssetCollectionRendererInterface $css_collection_renderer, AssetCollectionRendererInterface $js_collection_renderer, RequestStack $request_stack, RendererInterface $renderer, ModuleHandlerInterface $module_handler) { + public function __construct(AssetResolverInterface $asset_resolver, ConfigFactoryInterface $config_factory, AssetCollectionRendererInterface $css_collection_renderer, AssetCollectionRendererInterface $js_collection_renderer, RequestStack $request_stack, RendererInterface $renderer, ModuleHandlerInterface $module_handler, LanguageManagerInterface $language_manager) { @@ -106,6 +116,11 @@ public function __construct(AssetResolverInterface $asset_resolver, ConfigFactor + if (!isset($language_manager)) { + @trigger_error('Calling ' . __METHOD__ . '() without the $language_manager argument is deprecated in drupal:10.1.0 and will be required in drupal:11.0.0', E_USER_DEPRECATED); + $language_manager = \Drupal::languageManager(); + } + $this->languageManager = $language_manager;Same as AjaxResponseAttachmentsProcessor above...
-
+++ b/core/tests/Drupal/Tests/Core/Asset/AssetResolverTest.php @@ -68,6 +68,16 @@ class AssetResolverTest extends UnitTestCase { + /** + * A mocked English language object. + */ + protected $english; + + /** + * A mocked Japanese language object. + */ + protected $japanese;Could be worth typing these as LanguageInterface objects.
-
+++ b/core/tests/Drupal/Tests/Core/Asset/CssCollectionOptimizerLazyUnitTest.php @@ -0,0 +1,89 @@ + /** + * The data from the dumper. + * + * @var string + */ + protected $dumperData; + + /** + * A CSS Collection optimizer. + * + * @var \Drupal\Core\Asset\AssetCollectionOptimizerInterface + */ + protected $optimizer;I'm not sure why these are class properties. Is there a benefit? I guess this is c&p.
-
- 🇬🇧United Kingdom catch
This should address #37.
I'm not 100% on mixing property promotion vs. not on that constructor, but when you're overriding a constructor you end up mixing them anyway, so maybe it's OK. Hopefully we'll do a big conversion in 10.1.x so we don't have to keep making decisions like this as a one-off.
The phpstan issue is weird - I'm having to take the REQUEST_TIME stuff out of the baseline even though the code itself was added back (my machine struggles with a full phpstan run, so I haven't tried regenerating the baseline). Test failure should hopefully be fixed too.
- 🇧🇪Belgium borisson_ Mechelen, 🇧🇪
- 🇬🇧United Kingdom alexpott 🇪🇺🌍
-
+++ b/core/lib/Drupal/Core/Asset/AssetGroupSetHashTrait.php @@ -0,0 +1,46 @@ + // The asset array ensures that a valid hash can only be generated via the + // same code base. Additionally use the hash salt to ensure that hashes are + // not re-usable between different installations. + return Crypt::hashBase64(Settings::getHashSalt() . serialize($normalized));If we're going to use the hash salt here then I think we should be using
Crypt::hmacBase64(serialize($normalized), Settings::getHashSalt())- I think this is better because I'm not sure we should be using the hash salt like the core currently does.I think it is okay to not use the Drupal private key here as we do in other places where hmacBase64() is used.
-
+++ b/core/modules/system/src/Controller/AssetControllerBase.php @@ -0,0 +1,224 @@ + if ($received_hash === $generated_hash) {This should use hash_equals(). Not because I think that timing attacks are relevant here but because I think we should always use it when comparing hashes so we don't have to think whether or not we should use it.
- Re the phpstan thing... either mglaman or ondrej are being clever (well both are).. I think this is happening because we're deprecating the entire file here so we can ignore all the other deprecations in the file because it is on it's way out anyway.
-
- 🇬🇧United Kingdom catch
#1: Fair enough. Yeah prefer not to use the private key here since it's just a bit of hardening not actually cryptographically sensitive.
#2. Good point.
#3. Ahh I guess this might be it but had nothing to back it up, good to have it explained.
- 🇬🇧United Kingdom catch
Since the interdiff is trivial, going to go ahead and set back to RTBC pending the bot.
The last submitted patch, 381: 1014086-381.patch, failed testing. View results →
- 🇬🇧United Kingdom catch
The new failure is because we're exploding the filename on '_' and the new hash method generates hashes with underscores in.
I think we can just get rid of the prefixing of the filenames given they're in css/js folders and have .css and .js extensions, that way hash = filename and there's a bit less dancing around to get the hash value.
- 🇫🇷France nod_ Lille
That might be an issue if the hash starts with ad* or similar. We had those prefixes to prevent issues with adblockers.
A way to address this would be to use
explode('_', $file, 2) - 🇬🇧United Kingdom catch
@alexpott rightly pointed out in slack that we prefix the filenames not for discoverability, but so that they never start with 'ad*' to avoid overzealous adblockers from blocking them. So doing explode(..., 2) instead. interdiff against #381 (also what nod_ said).
Also while re-reviewing things I thought about another potential clean-up/simplification that this could unblock - 📌 Remove the aggregate stale file threshold and state entry Fixed
The last submitted patch, 384: 1014086-384.patch, failed testing. View results →
- 🇬🇧United Kingdom catch
Tentatively moving back to RTBC since the change from #381 is trivial.
- 🇬🇧United Kingdom catch
Another small tweak - moving the state service to the end of the new constructors in anticipation of 📌 Remove the aggregate stale file threshold and state entry Fixed so it's easier to remove.
- 🇬🇧United Kingdom catch
Have to change the arguments in the service definition too.
Also re-rolled.
The last submitted patch, 390: 1014086-390.patch, failed testing. View results →
- 🇬🇧United Kingdom catch
Tentatively back to RTBC again since only the argument order change and the explode() fix + a re-roll.
-
alexpott →
committed b957382 on 10.1.x
Issue #1014086 by catch, nod_, martin107, quietone, dww, mariacha1,...
-
alexpott →
committed b957382 on 10.1.x
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
So nice to finally see this fixed, and excellent change records! 👏
Automatically closed - issue fixed for 2 weeks with no activity.
- 🇺🇸United States cmlara
Opened 📌 Add an API method to get the contents of a CSS or JavaScript aggregate from a URL Closed: works as designed for discussion on what appear to be BC breaks from this issue.
- 🇺🇸United States xjm
This was already added to the 10.1.0 release notes draft.
- 🇦🇺Australia larowlan 🇦🇺🏝.au GMT+10
Updated release note to mention nginx impact
- 🇦🇺Australia mstrelan
This caused a fatal error for cl_server module: 🐛 Fatal error with Drupal 10.1 Closed: outdated .
Added a change record for the interface changes: \Drupal\Core\Asset\AssetResolverInterface::getCssAssets and ::getJsAssets now require a $language parameter →
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
I think I found a regression introduced by this issue: 🐛 Add additional test coverage for CssOptimizer Needs work .
- 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
That wasn't a real regression, it was a bug in a test 🙈
But now I found a genuine regression: 🐛 [regression] Since #1014086 generated CSS assets have absolute URLs without varying by url.site cache context Fixed .
- Status changed to Postponed
over 2 years ago 9:42am 14 April 2023 - 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
This is hard-blocked on the 🐛 [regression] Since #1014086 generated CSS assets have absolute URLs without varying by url.site cache context Fixed core issue.
- Status changed to Fixed
over 2 years ago 9:44am 14 April 2023 - 🇧🇪Belgium wim leers Ghent 🇧🇪🇪🇺
Too many tabs 🙈 #406 was meant for #3347181-8: 10.1.x compatibility: tests are failing against Drupal 10.1.x due to upstream changes → . Apologies for the noise!
Automatically closed - issue fixed for 2 weeks with no activity.





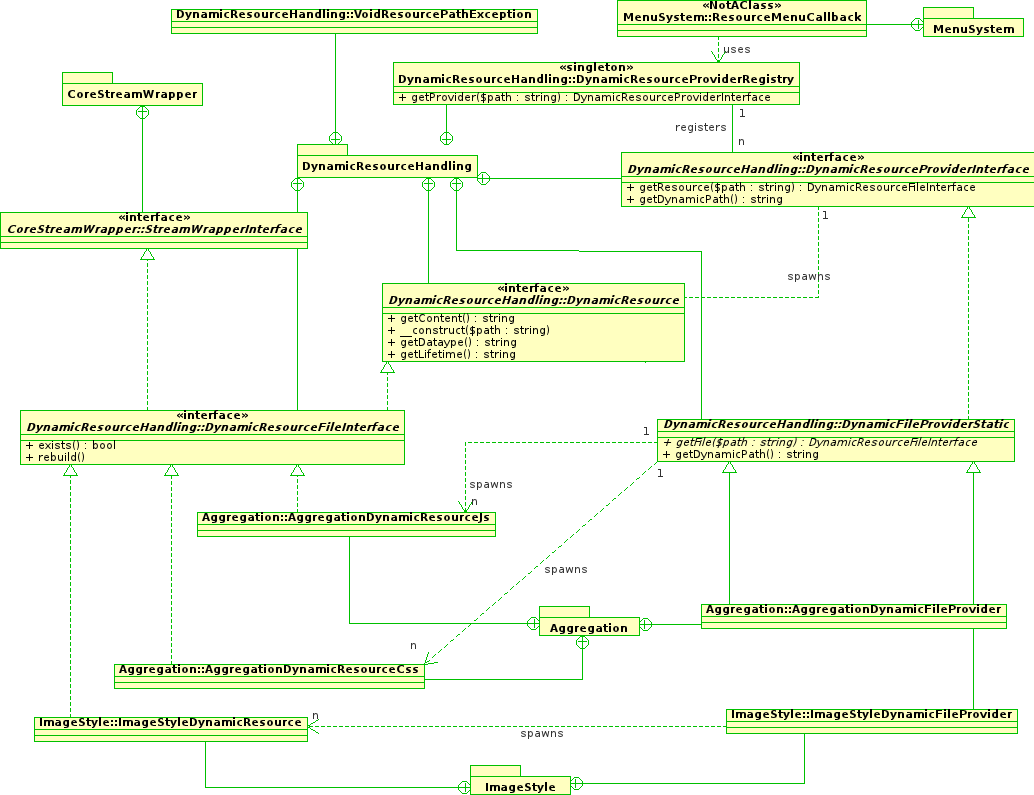{kind=link}
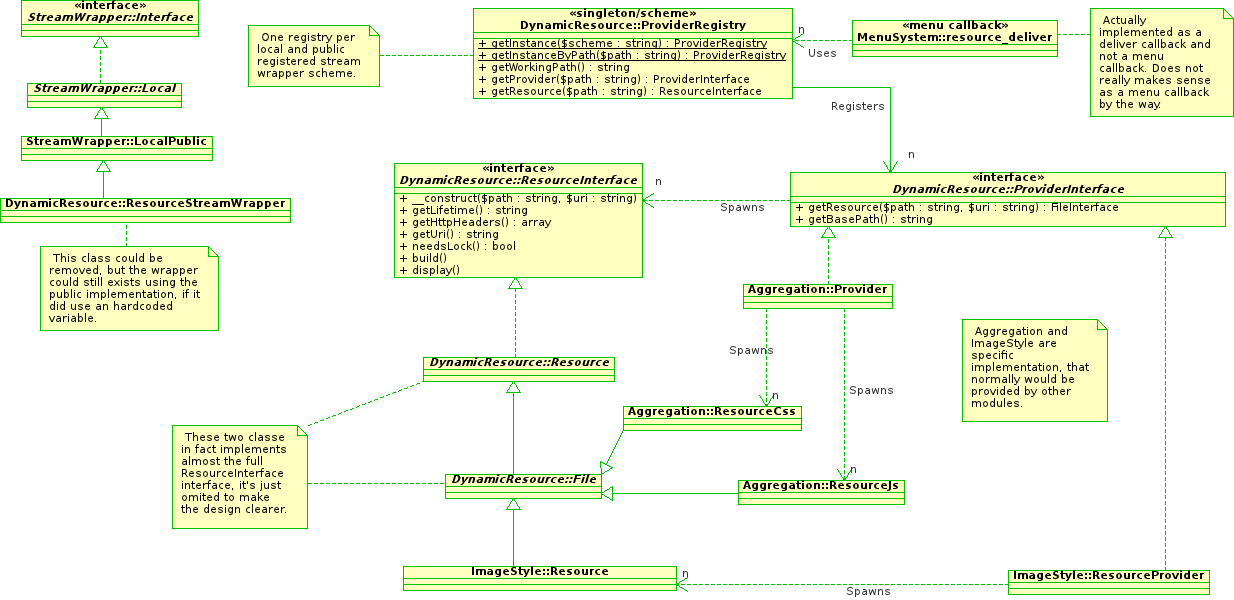{kind=link}