Please know that, for anybody experiencing this issue reaching this page that you can work around this by adding: <drupal-media data-align data-caption data-entity-type data-entity-uuid data-view-mode> in the allowed custom HTML configuration field in your filter format configuration UI.
Why should the console main application be registered as a service ? Symfony does not do this, and just:
$kernel = new Kernel($env, $debug);
$application = new Application($kernel);
$application->run($input);
Of course, it needs to be adapted to Drupal, but it seems much saner.
Why wouldn't Drupal have two different binaries, one "console" that work on a working site, and another such as "install" or "maintainance" that does everything that will need to run over a non bootstrapped site, spawning a generic application instance without the kernel (you can use the console component without any kernel). Then you just separate both types of commands, in the maintainance script you just add them to the application manually calling successively add():
use Drupal\...bla\Unbootstrapped1Command;
use Drupal\...bla\Unbootstrapped2Command;
use Symfony\Component\Console\Application;
use Symfony\Component\Console\Input\ArgvInput;
require_once dirname(__DIR__).'/vendor/autoload.php';
$application = new Application("Drupal core - maintainance");
$application->add(new Unbootstrapped1Command());
$application->add(new Unbootstrapped2Command());
$application->run(new ArgvInput());
And in the other script, you just bootstrap the DrupalKernel, inject it into a new Application instance, and run it.
This way it would make your life much simpler, ask people to tag using console.command their commands and register it into a Symfony\Component\Console\CommandLoader\ContainerCommandLoader instance, so they end up into the container and your application will discover them much transparently and you're good to go.
I see one small detail that could go wrong with #114: file names length will be proportional to the number of aggregated files, aside of that, it sounds OK.
I still think than using the state system for keeping track of aggregated files would be a rather good and failsafe solution instead of trying to dynamically lookup files names from the incoming URL.
Now that hook_library_info() is mandatory for all JS and CSS, the whole system will become a lot more predictable, my opinion is that the aggregation mecanism should be tied to this hook data instead of trying to do anything dynamically. Using it may help us to do all of this without any database table or generated identifiers or hashes (althought I'm not fully convinced, but I think this path should be explored).
EDIT: This means that the system is a lot less dynamic now, and it may solve some of the subrequests problem.
Here is what I actually do in the core_library module, this includes a SQL table too and is simpler IMO.
The table stores both the filenames array and hash along with a creation timestamp and a incremented version number.
Generated files are named hash-version so that older files are kept, ensuring that old caches somewhere (browser, proxy, etc...) will always have a resulting file in result, corresponding to the older cached page state.
Each time a CSS or JS file is modified, the creation timestamp raises, the table is updated with the increment set to +1 and the new creation time saved, resulting in a new CSS/JS file named hash-version+1. This way, one line only per aggregated "set" exists, but multiple versions coexist, and no filename lenght problem exist.
The hash is the table index, lookups are quite fast since the table won't massively grow on a production site.
The filename storage in a blob field allow two things, first as it is a blob, is supposedly not loaded into memory in caches by the SQL backend (depending on size and backend of course, I'm thinking about toasted columns in PgSQL) and also to fully rebuild the file on-demand when the URL is hit (no pre-aggregation is needed).
I came around a lot of thinking, and this is the best way I could find to manage those files, and it is efficient: the only drawback is the extra SQL query when either checking for version or building the file on first hit.
EDIT: Moreover with a bit of imagination the table could be replaced by any other backend easily (MongoDB, Redis, etc..) since there is one and only index/primary key which is the array hash.
#101 solution becomes overly complicated IMHO.
Good to hear. You can do a proper patch without changing the hash algorithm thought. You can use a variable for storing the mapping, but personnally I'd go for a database table, even thought the change would be more invasive (I'm thinking about patch size).
EDIT: I'm still against patching right now but if anyone wants it, you can do it: but it need more minimal than this: using the core hash algorithm and storing into the variable as a first attempt will be only a patch with only a menu callback and no change in the rest of the code.
We can't RTBC a patch that will attempt to write files with names longer than most FS supports. This patch is a no go. For example, ext3 has a limit of 255 chars for a single filename, using this patch, when browsing in the adminstration with standard profile (no modules) the file name is already 125 chars. We can't commit this, if we do, we'll doom a lot of sites.
pounard@blaster:/var/www/d8-git/www/sites/default/files/css
[Tue May 15, 00:12] $ ls -al
total 44K
drwxrwxr-x 2 www-data www-data 4096 May 15 00:12 .
drwxrwxrwx 11 pounard pounard 4096 May 15 00:05 ..
-rw-rw-r-- 1 www-data www-data 1682 May 15 00:08 core;modules;comment=comment.theme,core;modules;field;theme=field,core;modules;search=search.theme,core;modules;user=user.css
-rw-rw-r-- 1 www-data www-data 3864 May 15 00:08 core;modules;system=system.admin.css
-rw-rw-r-- 1 www-data www-data 7764 May 15 00:08 core;modules;system=system.base~system.theme.css
-rw-rw-r-- 1 www-data www-data 3960 May 15 00:08 core;modules;toolbar=toolbar,core;modules;shortcut=shortcut.theme~shortcut.base.css
-rw-rw-r-- 1 www-data www-data 16383 May 15 00:08 core;themes;seven=reset~style.css
pounard@blaster:/var/www/d8-git/www/sites/default/files/css
[Tue May 15, 00:12] $ php -a
Interactive shell
php > echo strlen('core;modules;comment=comment.theme,core;modules;field;theme=field,core;modules;search=search.theme,core;modules;user=user.css');
125
php > ^Dpounard@blaster:/var/www/d8-git/www/sites/default/files/css
[Tue May 15, 00:12] $ sudo touch "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaacore;modules;comment=comment.theme,core;modules;field;theme=field,core;modules;search=search.theme,core;modules;user=user.css"
touch: cannot touch `aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaacore;modules;comment=comment.theme,core;modules;field;theme=field,core;modules;search=search.theme,core;modules;user=user.css': File name too long
pounard@blaster:/var/www/d8-git/www/sites/default/files/css
[Tue May 15, 00:12] $
Agree about th potential DDoS problem, I wasn't even speaking of it. I don't know why switching to the concat method while the real world problem pointed out by the issue original post isn't due to the original hash/list mecanism?
URL have, per specification in the HTTP protocol, no length limit. But I'd like to highlight this: install a Drupal site with 100 modules, half of them brings you a CSS file, you will have URLs concating potentially 50 CSS, with a path length of 50 chars (I took this url as example: sites/all/modules/contrib/admin_menu/admin_menu.css which is not a long one), without taking into consideration the base url and other separators, this makes 50 * 50 = 2500 url length. This goes higher than the 2000 recommended max length for IE support. See http://stackoverflow.com/questions/417142/what-is-the-maximum-length-of-...
URL are also keys for caching and routing, in all the HTTP layer (client, proxy, routers, load balancer, proxy cache, CDN, HTTPd, PHP), and using extremely long keys may cause performance issues in any of those layers.
In some cases, the apache rewrite rule testing if a file exists can hit the file system limitations and fail. Even without rewrite, you can potentially hit file system limitations with many OS. This limit can be reached quite easily, see this kind of post for example http://serverfault.com/questions/140852/rewritten-urls-with-parameter-le...
EDIT: See also http://en.wikipedia.org/wiki/Comparison_of_file_systems
Did some research, and it seems those kind of problems can be quite recurring.
Whiie I can see the sexy side of URL concat, I think this is a no go, it doesn't scale, expose direct information about file directory structure of your PHP site, and may lead to weird behaviors and potential DDoS (both with arbitrary URL stressing the PHP side and extremely long URL stressing some browsers).
@catch I was a bit harsh with the "I won't wait another year", sorry again for that.
In reality this patch sounds better than that since it doesn't just concatenate file names. Still seems a weird way to go. I tried generating 30 random module names, between 5 and 12 char eachs, and use them as file name for CSS also, the current algorithm gives me an approximative 1300 chars length URL. [EDIT: which causes file system problems on my box, and is still really long]
@sun If the patch is a candidate for D7 backport, then just do the patch for D7 already and post it in a new issue set for 7.x, it indeed fixes real world problems, for a real world used version, but it doesn't make any sense for D8 because D8 is not a usable product yet, unfinished, in code as in design since it's in development process.
D8 is not out yet, and this can be solved in a much more elegant and efficent way, and we can do a major cleanup for a minimal cost by sharing the dynamic asset handling with image derivative generation --even if custom and simple, Assetic is yet another topic, more complex indeed--. This is what this issue has derivated to a year ago.
As long as D8 is not feature frozen, this must be designed first, coded later. Any code change makes going back in time difficult is a loss of time and energy for all people that actually wrote and reviewed it. Now is the time to think for D8, not the time to code if it's not thought first.
So, as you proposed, I could open a new issue, you said you will then you be happy to review it, I'm saying no: a lot of talking already happened in this one, there is no way to re-open them another place and start all over again from the beginning: you didn't reviewed the 60 first comments of the thread, or at least you didn't even commented them, I'm guessing you won't do it in another issue either.
I won't wait another year in a new issue that quotes the exact same posts that have been waiting here for a year.
EDIT: Sorry for being a bit nervous about this, but this is really something I did put a lot of effort into. I'd be happy not to see this year trashed away, especially when it tries (and succeeds as a stable module) to solve the exact same "real world problems" nicely, with a more global approach, with additional features (concurrent threads locking amongs other things) this patch actually doesn't solve.
This change will be obsolote the second the WSCCI patch will be commited. [EDIT: less than I thought due to a misreading]
I'm still thinking about making this a more generic API, that would handle both public files, images, css and js, would be a better way to go.
I see multiple issues in this patch:
- Yet another specific piece of code for a more general generic file handling use case
- It doesn't lock when building the CSS files, so we could have concurrent threads doing the same work at the same time, having potential conflicts when saving the files
- [EDIT: misread the patch for this one, sorry, thanks msonnabaum for pointing that out to me]
- The new WSCCI patch which being stabilized at this time introducing the request/response kernel from symfony will also bring a totally new way of handling this, which will make this code obsolete the second it will be commited to core
Going the way I proposed in #55 would reconcile this with the WSCCI initiative, of course my proposal is now obsolete too, but the design is much closer from what we'll have to implement in the end when the WSCCI patch will land.
Further, after some chats on IRC which conforted me in my opinion, I think we should orient this issue towards a generic listener based API approach for all file generation.
The idea would be to have the same mecanism as the Assetic library (thanks Crell for reminding me it exists). We have a listener on the kernel dispatch, it catches requests that matches files pattern, then does whatever it has to do depending on an internal logic in order to restitute a file.
This internal logic is what I was proposing in #55, but it can be different, but we desperatly need to have, at some point, assets handlers and providers which we need to be able to resolve dynamically at the listener/controller level.
We then have two path we could follow:
- Using Assetic, we need someone to take a serious look at this library: it may or may not integrate well with our need
- Implement our own internal logic (which doesn't sound that bad, the only difference with using a generic library is that the generic library will probably be full featured and more flexible)
One of the good sides in this approach is we can do it without having to register any router items. This sounds like a huge win to me.
@#67 Thanks for feedback. I agree for the menu system, it definitely can use it extensively instead of doing its own path split. I'm not sure it will fully remove the path split (how could we in a generic manner fully handle file extension and subpath). The idea behind the ruleset was leaving to business implementation what belongs to business implementation. This is arguable though. It could at least use the menu for one level deeper (provider level).
The whole goal of this is to centralize all three different ways of doing it into one generic enough to cover all actual needs.
Problem with file md5 is that it will be a lot slower. If the mtime is not accurate on the system, it should probably be overridable with an option (variable?).
Your module does a lot more than mine, and actually does not the same way! I'm totally pro-merging efforts if you want to, but we need to discuss how before.
EDIT:
@mickeytown2, I'm going to look more deep into your code in order to see where the patterns fit and how we could potentially merge. Don't hesitate to pm on IRC or mail via my contact page.
My code still remains a PoC of what could be such system in core, not sure the merge is something I want right now, but as promised, I'm going to study it.
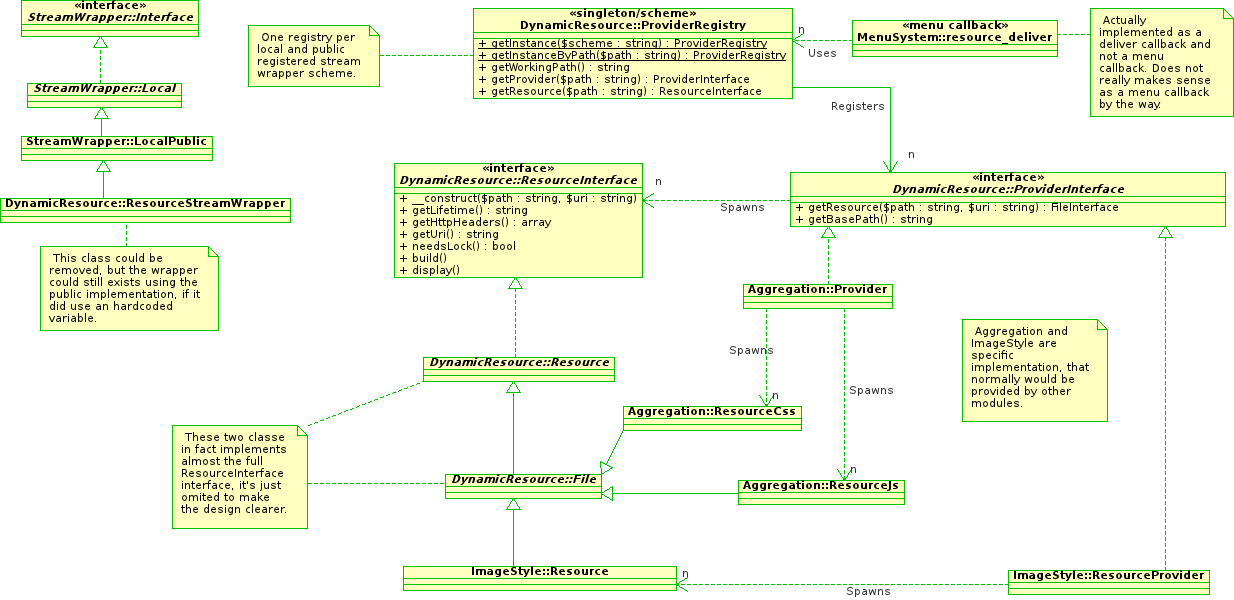
Did an alpha2 release (that will come in 5 minutes), and updated class diagram to fit the code.
{kind=link}
Pretty much same discovery mecanism as upper except I did put the URI and Stream Wrapper in the center of the design. Each public local stream wrapper sees it's base directory path handled by one registry (registries are singletons, on a per scheme basis). Providers can basically work on all schemes, this has really no importance, this is decoupled and allowed by design. A shortcut method of the registry allows to spawn resources directly (internally spawning the provider) which take cares of full and final resource URI build and pass.
File based resources are no longer extending the stream wrapper API (it was a huge mistake on my first diagram), but as each resource (not only files, all resources) have a fully qualified URI, you can use the adapted stream wrapper really easily. It makes the file based resources an unneeded abstraction, but it exists for code mutualization.
The overall code weight is 1000 lines, including CSS and JS integration, as well as Image Style file generation (basically OOP rewrite of the actual core menu callback), file delivering, HTTP headers handling, some basic configuration screens and form alters, a custom stream wrapper implementation, and all is fully documented (documentation included in the line count).
If anyone has some time to check/review/hate what I done, I'd be pleased to have some feedback.
EDIT: Just released an alpha3, this particular one solves the CSS and JS files modification problem. A version string is preprend to the URL (method used by some other software). When cache are cleared, each files of a computed map are being checked (once per hash only), if at least one of the files have a mtime superior to database entry creation, the version number is incremented. If a race condition happen (it can, it's not thread safe), the version string will be happened twice (which should make the whole stuff work anyway).
I have been working on http://drupalcode.org/project/core_library.git/tree/67dd838 (module Core Library). I actually implemented the schema upper, and written a totally useless sample implementation as well as the core CSS override (using #aggregate_callback override from style element info). It actually works quite well.
See the sub module 'resource' in http://drupalcode.org/project/core_library.git/tree/67dd838:/modules/res... for the implementation details (the lib/resource.inc file is where you should find the real useful code, as in the resource.module file you will find the deliver callback).
The implementation does not really fit the diagram I did the other day, but it looks pretty much like it, except I added the dynamically generated file $uri in the center of the design (which provide the link with the stream wrapper API) and removed the direct inheritance link with stream wrappers (much more cleaner).
@#60 Your module does *a lot* more than this, but I wanted to keep a simple implementation (while fully pluggable) that actually matches the issue's title.
Nice thanks, I'll look into it.
@mikeytown #57, I just looked up at advagg code, I think the design I made has pretty much ideas from it, but I think it's because catch originally express those. The main difference is I created an OOP design, much more centric, that mutualize it for anything, instead of having N menu items, my solution would only carry one for everything.
I might have looked at the wrong project branch, though.
Nevetheless that's where my design take an opposite from your module, it's interface centric and highly pluggable. It totally decouples business logic from the way to achieve it, and gives a set of extremely basic interfaces to ensure pure business code won't bother the middle complexity (which I solved partially) such as testing the file existence, locking, etc..
Eventually, some additional ideas to get further:
1. Create a directory for (content related static files) and (at the same level) for (dynamic content, not content related, static files or not).
In the long term, separating actual PHP code and remove it from the public web root dir would be a really good idea for security. Files (asset and resources) could then be elsewhere than the folder you commit into you git repositories when you do a project :)
2. Make the modules defines their CSS and JS in a declarative manner (the framework would be able either to move them at install time into the resources dir, either do it on demand with a specific provider and dynamic resource implementation, such as DefaultModuleCssFileResourceInterface for example.
Hello again! Long time I didn't post here.
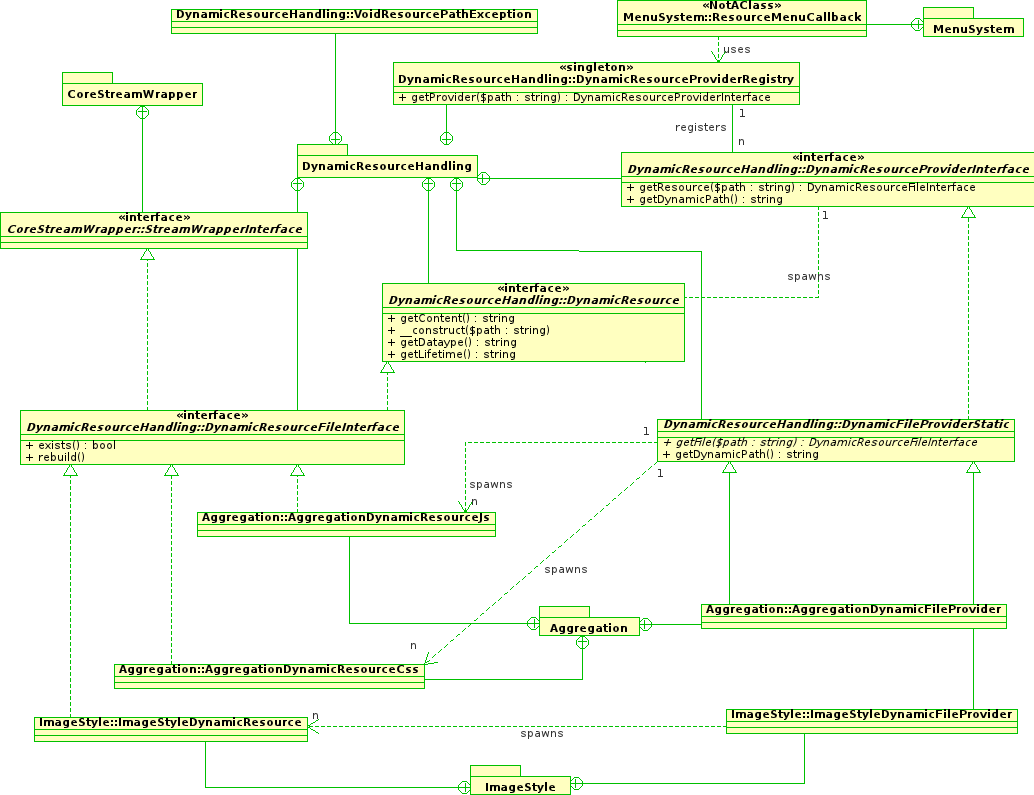
I have been doing some work about how the menu system could completely generate files on demand, based on partial file path. I finally ended up with a simple schema that could actually work.
You can see the diagram right here, in order to fully understand it, you might want to read what's next on this post with the diagram open side by side.
{kind=link}
Concept
The whole concept is oriented around a fully pluggable system based on interfaces.
@catch: Yes, fully "pluggable".
The main concept is split into those two statements:
- Menu doesn't care about specific implementations behind.
- Generated resources are static files, handled by Drupal, with or without a lifetime set.
Definitions
It's based on those definitions, that I arbitrary choosed:
Overall design
The main idea to implement it is to allow any (e.g. ImageStyle, core aggregation system, maybe Views for generating XML, anything that is a module or a core API) to register their providers to the system (See note ).
Each provider has a (provided by the getDynamicPath() method (See note ).
Runtime and error handling
Menu callback catch a lock on full file path (relative to files path). This lock will be released on errors, or when the file handling finished.
If the file is already locked, this callback shouldn't wait, it should either throw a:
- 409 Conflict
- 503 Service Unavailable
This first one seems the best, while the also exists, but it's WEBDAV specifics so we don't want to use it.
The can find which provider to use depending on a set of (extremely basic) rules matching using the partial file path from URL.
Each provider can spawn files instances using the partial relative path, relative to files folder. Never relies on absolute URL.
If the path means something, then it delivers the instance. If not, it throws an exception catched in the menu callback that triggers an HTTP error
- A real 404 this time, because the file really do not exists!
- Or a 500 or 503 error if the exception is not an
VoidResourcePathExceptionbut another technical error for any underlaying package.
This model allow the lowest code indirection possible, and will be extremely fast if no module messes up with hook_init(), which is the actual bottleneck of most Drupal 404 errors. Of course, Drupal shouldn't be bootstrapped on second attempt but that's up to the CDN/HTTPd/proxy configuration here maybe.
Real file handling
The instance can be an , case in which it implements the DynamicResourceInterface, and is able to give back content.
If, in the opposite, it matches a file that should be statically created (non volatile data for the most), then it should be an instance of DynamicResourceFileInterface that will actually also be a direct implementation of core existing StreamWrapperInterface (in most case a public specific implemention, but could any other).
This file instance using the upper named interface has a new method, which is rebuild(). This is purely internals, and should be lazzy called by the instance itself, after checking with exists() (See note ).
The menu callback would not be aware the distinction exists, it would just return the getContent() call, whatever happen (this is where to plug the lazzy rebuild for file-based implementation).
Each resource is able to give a lifetime (which can be ) this will help the system to give the right HTTP headers.
Magic pathes and ruleset
So I described pretty much of it, now there is something more for you to understand, a schema of the path ruleset applied:
http://mysite.com/sites/default/files/aggregate/css/SOMEUNIQUEID.css
| | |
We will ignore this. Ruleset! File identifier
Let's see that again:
http://mysite.com is base URL, throw it.
sites/default/files is file path, throw it.
aggregate designate our provider (registered partial path).
css/SOMEUNIQUEID.css file path given to provider (identifier).
So, we could have conflicts, basically. Imagine I do an image aggregator which registers: aggregate/images (this is valid), it would conflict with the already registered aggregate partial path.
The solution here (what I call the ) is basically to determine which one to use by parsing the partial path from the most specific towards the most generic.
Example: I give this URL to my menu callback:
http://mysite.com/sites/default/files/aggregate/images/foo.png
The discovery will based on a pre-ordered list of potential conflictual partial pathes when registering the providers (we probably would need cache then, but not that sure, needs benchmarking):
- aggregate/images
- aggregate
- imagestyle
Will then test the URL's one by one (either using substrings, either using regexes) in order to find the right one in order (See note ).
So if I give the URL quoted above, you will get this:
Now, if I give:
http://mysite.com/sites/default/files/aggregate/css/foo.css
This would give:
Providers are magic? CSS and JS specifics
Absolutely not! Each provider should carry its own business code.
The simplest example is for CSS and JS aggregation. Actually when core derivate a new JS/CSS file, it build a hash of the new file.
The CSS/JS implementation should build a random and unique identifier (See note ) and store it in a database table, along with the full file list. Then, on menu callback call it can restore it and build the real file. The beauty of this model is once it's build, we will never query again the database because HTTPd will catch the real static file (See note ).
These files entries must not be cached in a bin, but in a real table once the JS/CSS aggregation derivated to a URL, this must be non volatile in order to handle further requests from outdated browser's or proxies cache.
And what now?
Give 1 hour, I make you the code for the original design.
Give 2 extra hours, I make the CSS/JS partially working.
Give 3 extra hours, I overload the actual Image Style handling, do the menu alter, and backport it to D7 gracefully.
Then give me 5 hour of your time, and we all discuss this, fix bugs, evolve the API or throw it away and pass to another solution.
Footnotes
- This can be done either using a hook_info(), or in modules .info file, or anyother discovery system, this is where the system becomes fully pluggable and will be integrated with future plugins system discussed into the WSCCI initiative.
- It can also be provided by hook metadata, this not fixed anyway and won't change the hole design.
- Indeed, we could get here because the HTTPd didn't find the file, while another thread could have created it (even with the locking framework, race conditions can happen).
- Substrings would probably be faster, that's why I want the schema to respect the KISS principle (Keep It Stupid Simple) and not implementing the whole matching ruleset using complex parametrable regexes (a lot slower).
- Why not a UUID V4 here, this is exactly the kind of purpose they have been created for.
- Actually the Image Style module (formerly ImageCache for D6) already works this way, we need to keep this!
After a first reading it seems not bad, I'll take a deep look at it later.
catch +1 this is a detail, and the solution will come with a new API. We can't solve details without having taken the time of the reflexion of the overall design. Actual solution isn't the best, but at least it works and it's not the main problem here.
I don't feel this issue shoud live by itself, and that's why I though yesterday:
We have to focus on the simple goal we want to achieve for the full aggregation part
But, we have also secondary goals here
Considering all this points here
I think that is issue should probably be the last one to be fixed within all others.
The first point you have to consider is because you start to think about using the same mecanism as image styles, and talking CDN integration, you have to merge this issue with the image style subsytem one itself. This in order to find one and only technical solution for this, with a common code base. Integrating this problem around the stream wrapper API seems to be the smarter way to do it. To be clear, even the menu callback itself should be a common menu entry over the files directory, for all, and then derivated running code would live in specific stream wrapper implementations for example. Factorise the problem, factorise the solution, and it will work as-is without any code duplication for all the files and CDN integration problems.
This issues does not belong to the CSS/JS aggregation problem, it should be a global pattern in the core for all subsystems tied to the lowest level API possible.
Because of this statement, the CSS/JS aggregation problem should only focus on the first three point I quoted above. Catch already has part of the solution in agrcache module, and I do have some of them in core_library module, let's start thinking with some nice component diagrams and schemas that will be way more understandable that any other potential written argument here.
The first thing on which to concentrate of is to destruct and throw away the actual implementation, and build one, API and backend orientend, static and declarative API, with no I/O and delayed possible aggregated files construction. Then, let people that worked on the stream wrapper implementation solve the real CDN problem on their side. Once they found a solution to this problem, plugging the new fresh aggregation API over it would be something like 2 lines of code, if they did it right.
EDIT: Some typo, sorry for my poor english.
Re-EDIT: <strong>'ed some important parts.
#31, #32 and a lot of other posts: We are not arguing the right details here. Core aggregated files naming is the only good part of core aggregation mecanism and I really don't see why changing it. I might have expressed myself wrongly at start.
A physical fileS MD5 is almost as hard to guess that the answer of what is the universe. I won't worry about this.
The only thing that really stops the DDoS is server side check in order to know if the hash has been registered or not (like the form tokens for example), the registration must a server generated hash, some sort of unique id. If a user try to DDoS you with an existing one, it'll just try to DDoS the CDN :) If a user tries with a non existing hash, it'll just the exact same as flooding your full homepage, you just can't stop it.
The only thing I warned you about is that the server should not respond to client orders (what I mean here is that the file selection should not come from any specific client URL but should be pre-determined by the server itself).
EDIT: Better expression.
I'd prefer to speak about the original issue, which is nothing such as the files TTL. We are talking about how to generate them, not about how to remove them. The deletion algorithm can be implemented outside this issue, and can be über complex if you want to, it does not belong to this thread IMHO.
When CSS/JS aggregated files go missing because of a minor changes, the site goes unstyled, the ads don't show up, and features don't work. Unacceptable. Period.
Using a MD5 hash of the files themselves to create the CSS/JS files hashes leads to no cache hits the first time then never ends up with a blank site.
Then again, serving a 1 day TTL'd cached page will then give the oldest outdated CSS file hash, that would the same TTL than the page itself. Then you have 2 different choices here, either you keep outdated files some days (but mark them somewhere as being outdated so you can remove them later) or just put a higher TTL on them to ensure that cached outdated pages will live less time than them.
There are probably a lot of other solutions, and that's not the real problem here. You don't need anything than a hash, you don't need GET parameters, the problems we are currently arguing about right now is nothing resolved by the hash itself.
I know that Drupal core developers are emotionally attached to high dynamism, but the CSS/JS case, we are talking about pure static files, that will never, ever be modified except if modules are updated. When modules are physically updated, then wipe out the aggregated files cache, that should be more than enough.
Or just let the site admin press a button to tell the system he manually updated a module.
If you update to 1.1 your lib, and the hash i based on md5'ing the files, then the hash changes and the cache will be refreshed. Akamai and Varnish cache will gracefully die after their TTL or when their memory will be filled by new data. I don't see no problem with using nothing else but a single hash, depends on how you compute it.
And again, that's not a real problem, you don't update a production site every day. When you do update a production site, you are going to have problems with reverse proxy cache anyway, whatever happens at least during the page TTL.
EDIT: Again, we can afford md5'ing the files because it will happen only when the site is in development. Once the site is put in production mode, every hash will already have been computed. JS and CSS files are not something that evolves like you data, there is no dynamism at all.
You don't have that many solutions. If you want to limit the number of generated files, then you have the files to be the more static as possible as you can.
If I was an horrible dictator, I would force the whole CSS/JS handling to be highly declarative (each module would have to expose their own CSS and JS files in a declaritive way, either in the .info or in a custom hook) then I would aggregate all of them on every page, and this problem would be solved.
Because sometimes, for some execptions, some files should not be aggregated on every page (and the dynamic inclusion should be the exception in a static oriented pattern, the actual D7 core pattern is upside down) then some options for controlling that should be declared in this files registry, statically again.
Plone works this way as I understood.
Static register of every CSS and JS files would allow you to make the aggregated files fully predictable, then the dynamic bits of it would be the exceptions in the pattern, and you could treat it differently (maybe not aggregating them at all would be a simple solution). It would also allow sysadmins to override the aggregated files and profiling the aggregation the way that fits more to their physical environment.
Never let your logic be controlled by GET parameter or URL generation logic. Aggregation and menu callback should let visible as URL's only server side computed hashed. On a production site, the variable will never grows since all hashes will already have been generated on most pages.
If the URL building logic is predictable you can then have malicious hack attempt or DDoS attacks based on that.
There is nothing ugly about storing hashes with associated files array in server side as long as you don't generate different aggregated file on every page (which is quite dump thing to do). The whole aggregation goal is to have the less files possible it can have to ensure that a single client browsing on site won't fetch a new CSS and JS file each new page it comes to.